
人工智能
最新课程
- 电源认证-线上直播答疑-第1期
- TI 高精度实验室 - 数据转换器:使用精密ADC测量RTD
- 如何利用高速比较器优化系统设计
- TPS546D24S 和 TPSM8S6C24 中的扩展安全功能
- TI 高精度实验室 - 仪表放大器
- 高侧开关深入研讨
- TI 高精度实验室 - 微控制器 (MCU)
- TI 高精度实验室 - CPU内核
- 三种直流/直流控制模式的实际比较
- 电源多路复用器深度培训
热门课程
TI-RSLK 模块 3 - 讲座视频 - ARM Cortex M 组件




大家好,
我是
我们将讨论
正如我上次说过的,
了解的越多,
计算机实际上
代码的,也就越有可能
系统工程师。
因此,即使您使用
我也认为您
或汇编级别了解
执行方式。
因此,我们要
Cortex
调试
让我们开始吧。
让我们从逻辑
正如您知道的,我们将
因此,如果我们以“1”结束,
如果我们以零结束,
这里的或运算
因此,如果我们与一执行
如果我们与零执行或运算,
我们将
或将两个不同
合并到一个值中。
我要讨论的
运算是异或。
因此,如果我与一执行异或
换句话说,如果我进行
异或运算,它将从一
如果我与零执行异或
那么,再说一次,我们
这里是汇编
这里是操作码。
这些是操作数。
这恰好是寄存器
具体而言,在这里,
都沿着这个方向执行。
换句话说,这里的
R1
并将结果放回到
您需要从这
我们也会在
这称为按位
那么,在本例中,
与
在这里,我有一些
已位于
可以看到会
它是按位发生的。
因此,如果您选择
让我们看看位八
我们会看到它将
以及
对齐,然后将该值
它会对全部
再说一次,逻辑运算
移位运算本质上
换句话说,向右
向左移位
但您需要了解的
一个事实,即您需要
无符号数还是
对您而言非常重要。
因为如果它是
您需要进行
零移位到这里,您
相反,如果它
那么您将在将其
最高有效位。
因此,了解该运算的
即您看到您具有
因此,我们将在对该
您应该知道您具有的
无符号数,这一点很重要。
当您向左移位时,
还是无符号数
我们将放入一个零。
再说一次,运算
因此,它会获取
将其右移多次,然后
寄存器中。
因此,我们将使用
执行乘和除。
这里的重点是,
您必须知道它
无符号数。
算术运算
我将获取两个
将它们相加。
P
但这里的问题是,
如果我获取该
另一个
这就导致了一种
可能无法重新
寄存器中,我可能会出错。
该错误
该情况会在加法
它实际上在
如果我获取一个
数字相乘,那么我
我得到
那么,这是一条
那么,当您编写您的
对该溢出情况的担忧时,
第一件事是,我们将
预测中间结果的
并确保该值
因此,这通常意味着
我们的输入的范围,并且
那么,例如,如果您知道
换句话说,我知道我的数字
我获取该数字,然后
我知道它可能达到的
这是它可能达到的最大值。
因此,理论上而言,
因此,我知道该数字
因此,如果我可以
知道该限制是
在理论上证明,
任何中间结果都
我们将用于解决
将其升级至
因此,我可能必须在
或者我可能必须获取
模式下执行它们。
因此,升级将
在该更高的
然后再将其降级回到原来的精度。
因此,您需要
数字的大小,
因为我们在该处理器结构中
当我们执行除法时,很显然,
另一个可能
称为掉出的问题,
此外,它还会在向右移位上
向右移位是除法。
基本而言,掉出
正如您看到的,
如果我获取数字
这在本质上
因此,我将丢失我的
因此,再说一次,我要
而导致灾难性的信息
灾难性的信息
除法或向右移位
就像移位、加法、
和除法一样,您
它是有符号数
使用一个有符号数
进行加、
是没有意义的。
因此,我们无法对两个
算术运算。
这没有任何意义。
基本而言,我们必须
更大的有符号数,
一起进行运算。
这是加法指令。
再说一次,它的
它获取第二个操作数,
将其与中间操作数
操作数进入这里。
请注意,在汇编级别,
进位标志会在发生
溢出
不幸的是,C
当我们执行加、
我们必须
或者我们必须
以防发生溢出。
当我们获取
指令。比较指令
但它不在
存储结果,
乘法和除法
先前已提到,
知道您的数字是
实际上,我们
用于无符号数/除法与
就像所有
该运算沿着
您可以看到它
因此,它获取
乘以该数字,然后
存储在该寄存器中。
这是前一个讲座中
访问变量的原理。
那么这位于
那么我在这里有一个
我在那里有
我们上次看到了
执行两个步骤。
第一步是
这是该指令。
这里是指针。
那么,这是指向
那么,这里的第一条
该
然后,我们可以使用
在本例中,
现在,我们
并除以五,
这里是乘法指令。
它获取
然后将结果存储回到
除法指令获取
除以
再说一次,我们看到用于
第一步是使一个
现在,该访问
因此它要将结果
总之,需要
总之,需要考虑它是
堆栈非常重要。
我们将在整个
我们可以将其
比如我们有
我们希望临时存储它,
这是后进
换句话说,我可以保存某些
它还是编译器
方法之一,
变量也是
不过,让我们
堆栈位于
当我绘制一个
我要将零地址
将
在这里的某个
分配一些空间。
现在,很显然,它必须
然后,我将设置
以指向该位置。
我将定义堆栈
堆栈的顶部
我最近,上次
因此,如果我查看
该堆栈指针将最初
元素。
我将在这里
最初等于
R2
我将执行
那么,这是第一条
它的工作方式是,
它将递减四。
这是因为,您应该
是
或四个字节。
因此,为了腾出空间,
我将在该位置
因此,请记住,
我要将零
然后,我执行
它存储一,递减堆栈
进行存储。
第三条指令,使
然后在该位置使
因此,在任何给定的
都会指向数据,并且
最后入栈的数据。
因此,堆栈的顶部
入栈的数据。
但是,出栈按照
这是出栈。
现在,我要
因此,这现在也
第五条指令,弹出
R4
堆栈现在与
实现了平衡。
那么,三个入栈,三个
移动了一些数据。
再说一次,入栈指令
而出栈会首先
那么,再说一次,
当您在计算机上进行
实际看到的东西。
因此,在整个
都将讨论
它是一种用于
那么,具体而言,
如何定义和
这是一个函数。
它是一种用于
因此,如果我有大量的代码,
这是低级别的代码
而这是高级别代码。
那么,函数
这些点是伪操作,
这三个。
因此,当这执行时,
函数调用。
因此,该函数的
是函数调用,
在这里看到
我们将看到这是怎么工作的。
让我们来执行它。
第一条指令将
那么,在我的寄存器中,
R0
第二条指令是
分支连接上会
然后,它要将连接
设置为返回地址,
返回地址是
那么,这里的
调用函数之后的指令
它插入到
然后,它将更改或
使其等于函数地址。
程序计数器在这里。
就是这样。
因此,要执行的
该指令,第三条指令。
我们以前看到过它。
它要将
因此,R1
那么,第三条
要获取该存储到
因此,我初始化
但这里有趣的是
构造,以及一条
BXLR,它基本上会
并将其放置到
但连接寄存器
这是程序计数器
因此,第六条指令将是
另一个子例程调用。
那么,让我们来执行它。
现在连接寄存器
程序计数器已
然后它将执行
10,
现在,这恰好是
这不是一个非常好的
但是它会返回一个介于
请注意,它使用了
它在
然后,它还将使用
因此,R0
但
实际上是子例程
它获取连接寄存器
计数器中。
因此,现在程序计数器
那么,第
它将存储值,
那一个中。
那么,现在我们使
现在,在第
随机数生成器,
将存储在这里。
现在,第
因此,我们在
那么,这里的重点是,
来降低复杂性,
并且我们将
来调用函数。
我们将使用
这是有关条件
这里的重点是,需要
还是有符号数。
由于我们有一组
基本而言,我们会
一个寄存器中。
我们将使用比较指令,
进行比较。
然后,我们将
如果该条件为真,
那么,这就是我们
再说一次,我们
存储到一个寄存器中,将某个
然后进行比较。
然后,我们可以
只要两侧都是
两个值都是有符号数,
我们使用循环
那么,在本例中,
G1
不断地运行
有时,我们会将某个
那么,我们可以通过
在本例中,R4
我们将使
然后,我们将退出。
这就是我们将
总之,我们
概述了
我建议您打开
您的
是否还有什么不明白的地方。
在本次讲座中,
可以使您成为
重点是:需要考虑
太大而无法存储;
这会在除法或向右移位上
确保您了解您的
还是
随着我们继续学习,
因为这些指令专门
数字运行。
非常感谢,祝您
再说一次,在那里稍微深入
该汇编语言的某些部分。
-
 未学习 TI-RSLK 模块 1 - 讲座视频 – 使用 CCS 在 LaunchPad 上运行代码
未学习 TI-RSLK 模块 1 - 讲座视频 – 使用 CCS 在 LaunchPad 上运行代码
-
 未学习 TI-RSLK 模块 1 - 实验视频 1.1 – 安装 tirslk_maze
未学习 TI-RSLK 模块 1 - 实验视频 1.1 – 安装 tirslk_maze
-
 未学习 TI-RSLK 模块 1 - 实验视频 1.2 – 安装 CCS 和调试
未学习 TI-RSLK 模块 1 - 实验视频 1.2 – 安装 CCS 和调试
-
 未学习 TI-RSLK 模块 1 - 实验视频 1.3 – 运行 TExaS 逻辑分析仪
未学习 TI-RSLK 模块 1 - 实验视频 1.3 – 运行 TExaS 逻辑分析仪
-
 未学习 TI-RSLK 模块 1 - 实验视频 1.4 – 运行 TExaS 示波器
未学习 TI-RSLK 模块 1 - 实验视频 1.4 – 运行 TExaS 示波器
-
 未学习 TI-RSLK 模块 2 - 讲座视频 – 电压、电流和功率
未学习 TI-RSLK 模块 2 - 讲座视频 – 电压、电流和功率
-
 未学习 TI-RSLK 模块 2 - 实验视频 2.1 – 测量电容器的阻抗
未学习 TI-RSLK 模块 2 - 实验视频 2.1 – 测量电容器的阻抗
-
 未学习 TI-RSLK 模块 2 - 实验视频 2.2 – LED (I,V) 响应曲线、指数关系
未学习 TI-RSLK 模块 2 - 实验视频 2.2 – LED (I,V) 响应曲线、指数关系
-
 未学习 TI-RSLK 模块 3 - 讲座视频 - ARM Cortex M 架构
未学习 TI-RSLK 模块 3 - 讲座视频 - ARM Cortex M 架构
-
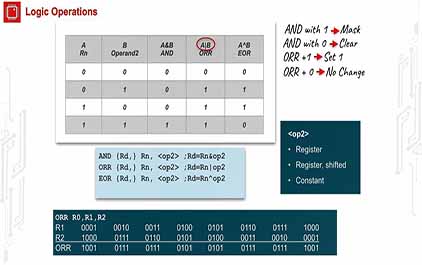 未学习 TI-RSLK 模块 3 - 讲座视频 - ARM Cortex M 组件
未学习 TI-RSLK 模块 3 - 讲座视频 - ARM Cortex M 组件
-
 未学习 TI-RSLK 模块 3 - 实验视频 3.1 - 调试解决方案、可视化、断点和单步执行
未学习 TI-RSLK 模块 3 - 实验视频 3.1 - 调试解决方案、可视化、断点和单步执行
-
 未学习 TI-RSLK 模块 4 - 讲座视频 - C 语言编程
未学习 TI-RSLK 模块 4 - 讲座视频 - C 语言编程
-
 未学习 TI-RSLK 模块 4 - 讲座视频 - 设计
未学习 TI-RSLK 模块 4 - 讲座视频 - 设计
-
 未学习 TI-RSLK 模块 4 - 讲座视频 - 调试
未学习 TI-RSLK 模块 4 - 讲座视频 - 调试
-
 未学习 TI-RSLK 模块 4 - 实验视频 4.1 - 调试解决方案、可视化、变量、单步执行
未学习 TI-RSLK 模块 4 - 实验视频 4.1 - 调试解决方案、可视化、变量、单步执行
-
 未学习 TI-RSLK 模块 4 - 实验视频 4.2 - 调试解决方案、可视化、断点、单步执行
未学习 TI-RSLK 模块 4 - 实验视频 4.2 - 调试解决方案、可视化、断点、单步执行
-
 未学习 TI-RSLK 模块 5 - 讲座视频 - 电池和电压
未学习 TI-RSLK 模块 5 - 讲座视频 - 电池和电压
-
 未学习 TI-RSLK 模块 5 - 实验视频 5.1 - 测量电池的电压和电流
未学习 TI-RSLK 模块 5 - 实验视频 5.1 - 测量电池的电压和电流
-
 未学习 TI-RSLK 模块 5 - 实验视频 5.2 - 连接电机驱动器和配电板
未学习 TI-RSLK 模块 5 - 实验视频 5.2 - 连接电机驱动器和配电板
-
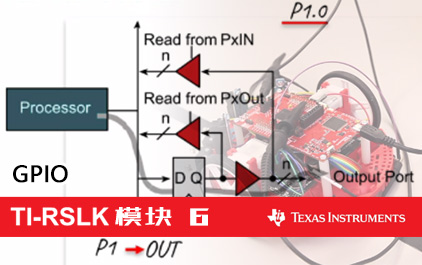 未学习 TI-RSLK 模块 6 - 讲座视频 - GPIO MSP432
未学习 TI-RSLK 模块 6 - 讲座视频 - GPIO MSP432
-
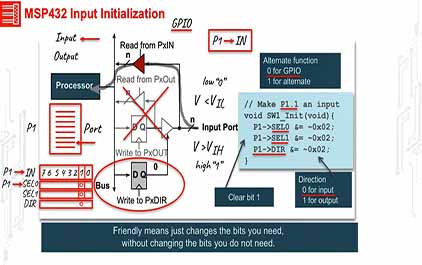 未学习 TI-RSLK 模块 6 - 讲座视频 - GPIO 编程
未学习 TI-RSLK 模块 6 - 讲座视频 - GPIO 编程
-
 未学习 TI-RSLK 模块 6 - 实验视频 6.1 - 演示反射传感器的工作原理
未学习 TI-RSLK 模块 6 - 实验视频 6.1 - 演示反射传感器的工作原理
-
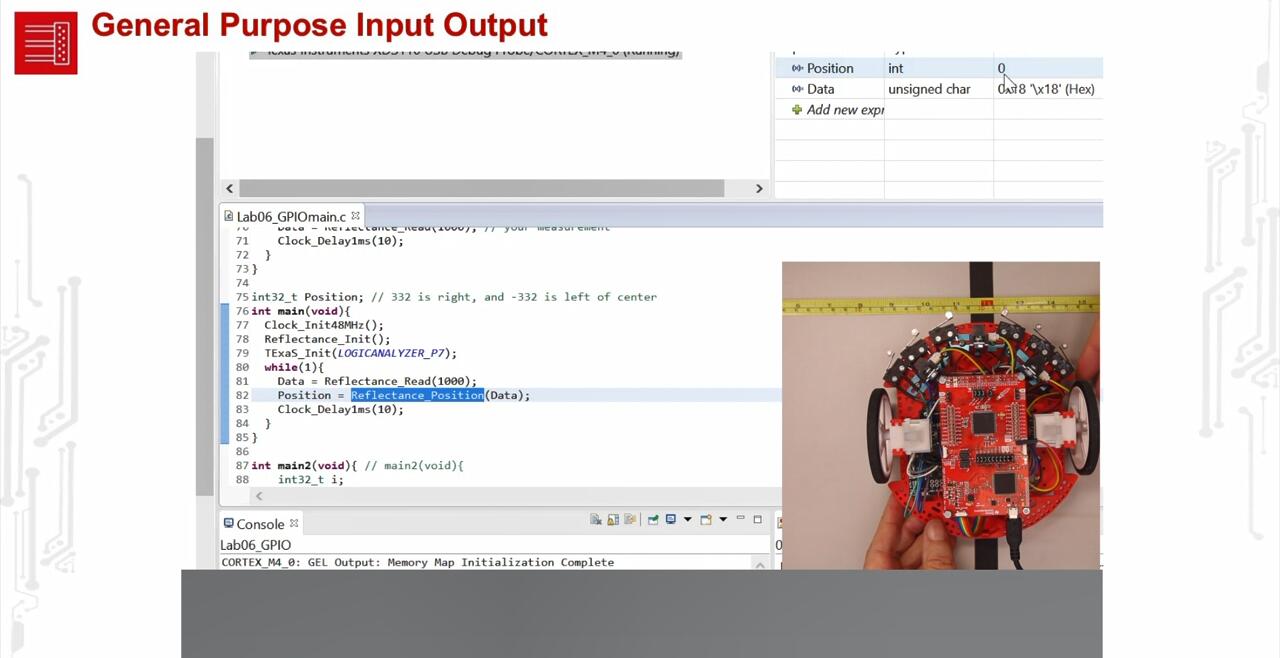 未学习 TI-RSLK 模块 6 - 实验视频 6.2 - 演示实验解决方案 - 测试线路传感器
未学习 TI-RSLK 模块 6 - 实验视频 6.2 - 演示实验解决方案 - 测试线路传感器
-
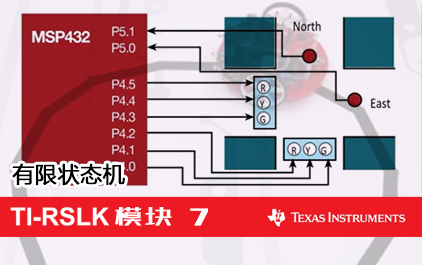 未学习 TI-RSLK 模块 7 - 讲座视频 - 有限状态机理论
未学习 TI-RSLK 模块 7 - 讲座视频 - 有限状态机理论
-
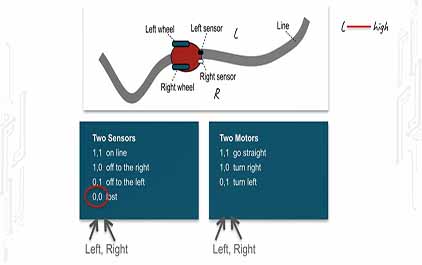 未学习 TI-RSLK 模块 7 - 讲座视频 - 有限状态机线路跟踪器
未学习 TI-RSLK 模块 7 - 讲座视频 - 有限状态机线路跟踪器
-
 未学习 TI-RSLK 模块 7 - 实验视频 7.1 - 运行 FSM 启动代码
未学习 TI-RSLK 模块 7 - 实验视频 7.1 - 运行 FSM 启动代码
-
 未学习 TI-RSLK 模块 7 - 实验视频 7.2 - 运行解决方案代码 - 设计更好的 FSM
未学习 TI-RSLK 模块 7 - 实验视频 7.2 - 运行解决方案代码 - 设计更好的 FSM
-
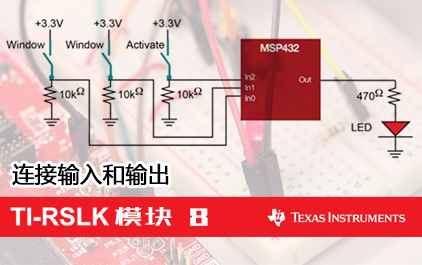 未学习 TI-RSLK 模块 8 - 讲座视频第一部分 - 开关
未学习 TI-RSLK 模块 8 - 讲座视频第一部分 - 开关
-
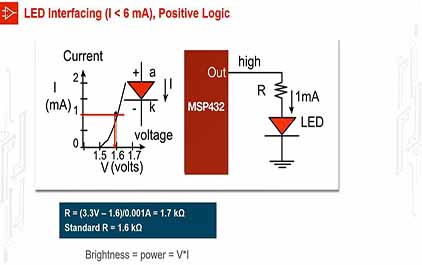 未学习 TI-RSLK 模块 8 - 讲座视频第二部分 - 连接输入和输出 - LED
未学习 TI-RSLK 模块 8 - 讲座视频第二部分 - 连接输入和输出 - LED
-
 未学习 TI-RSLK 模块 8 - 实验视频 8.1 - 连接开关和 LED 以及调试
未学习 TI-RSLK 模块 8 - 实验视频 8.1 - 连接开关和 LED 以及调试
-
 未学习 TI-RSLK 模块 9 - 讲座视频 - SysTick 计时器 - 理论
未学习 TI-RSLK 模块 9 - 讲座视频 - SysTick 计时器 - 理论
-
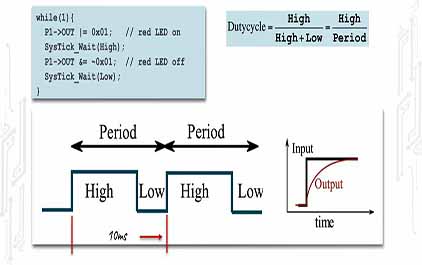 未学习 TI-RSLK 模块 9 - 讲座视频 - SysTick 计时器 - PWM
未学习 TI-RSLK 模块 9 - 讲座视频 - SysTick 计时器 - PWM
-
 未学习 TI-RSLK 模块 9 - 实验视频 9.1 - 演示通过调整占空比来运行检测信号
未学习 TI-RSLK 模块 9 - 实验视频 9.1 - 演示通过调整占空比来运行检测信号
-
 未学习 TI-RSLK 模块 9 - 实验视频 9.2 - 演示通过运行正弦波输出来调整功率
未学习 TI-RSLK 模块 9 - 实验视频 9.2 - 演示通过运行正弦波输出来调整功率
-
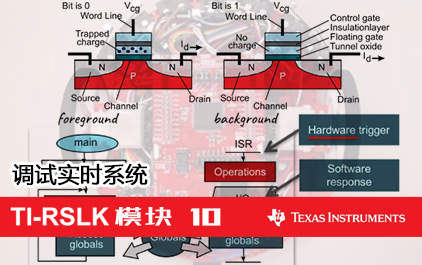 未学习 TI-RSLK 模块 10 - 讲座视频 - 调试实时系统 - 理论
未学习 TI-RSLK 模块 10 - 讲座视频 - 调试实时系统 - 理论
-
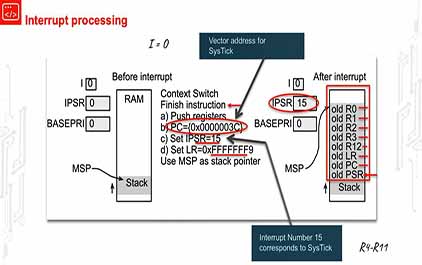 未学习 TI-RSLK 模块 10 - 讲座视频 - 调试实时系统 - 中断
未学习 TI-RSLK 模块 10 - 讲座视频 - 调试实时系统 - 中断
-
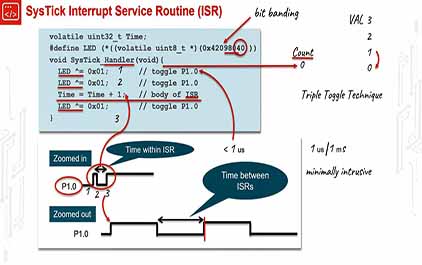 未学习 TI-RSLK 模块 10 - 讲座视频 - 调试实时系统 - SysTick 中断
未学习 TI-RSLK 模块 10 - 讲座视频 - 调试实时系统 - SysTick 中断
-
 未学习 TI-RSLK 模块 10 - 实验视频 - 演示运行线传感器和黑匣子记录器
未学习 TI-RSLK 模块 10 - 实验视频 - 演示运行线传感器和黑匣子记录器
-
 未学习 TI-RSLK 模块 11 - 讲座视频 - 液晶显示屏
未学习 TI-RSLK 模块 11 - 讲座视频 - 液晶显示屏
-
 未学习 TI-RSLK 模块 11 - 实验视频 11.1 - 演示 LCD 界面
未学习 TI-RSLK 模块 11 - 实验视频 11.1 - 演示 LCD 界面
-
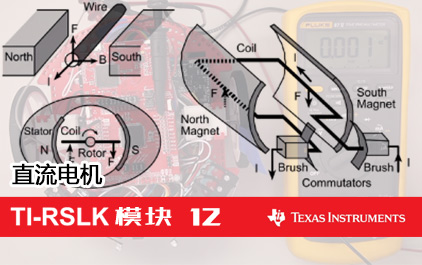 未学习 TI-RSLK 模块 12 - 讲座视频 - 直流电机 - 物理
未学习 TI-RSLK 模块 12 - 讲座视频 - 直流电机 - 物理
-
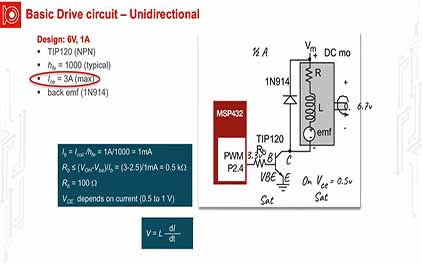 未学习 TI-RSLK 模块 12 - 讲座视频 - 直流电机 - 接口
未学习 TI-RSLK 模块 12 - 讲座视频 - 直流电机 - 接口
-
 未学习 TI-RSLK 模块 12 - 实验视频 12.1 - 演示电机基础知识
未学习 TI-RSLK 模块 12 - 实验视频 12.1 - 演示电机基础知识
-
 未学习 TI-RSLK 模块 12 - 实验视频 12.2 - 演示机器人以预设模式移动
未学习 TI-RSLK 模块 12 - 实验视频 12.2 - 演示机器人以预设模式移动
-
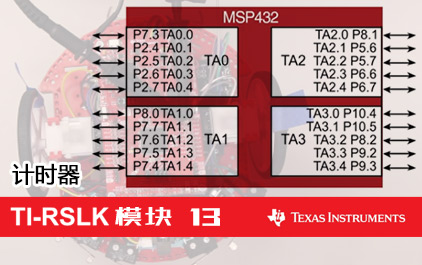 未学习 TI-RSLK 模块 13 - 讲座视频 - 周期性输入
未学习 TI-RSLK 模块 13 - 讲座视频 - 周期性输入
-
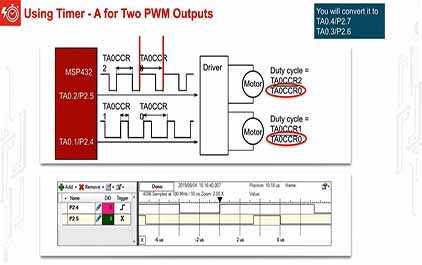 未学习 TI-RSLK 模块 13 - 讲座视频 - 脉宽调制
未学习 TI-RSLK 模块 13 - 讲座视频 - 脉宽调制
-
 未学习 TI-RSLK 模块 13 - 实验视频 13.1 - 通过计时器产生的 PWM 输出来旋转电机
未学习 TI-RSLK 模块 13 - 实验视频 13.1 - 通过计时器产生的 PWM 输出来旋转电机
-
 未学习 TI-RSLK 模块 13 - 实验视频 13.2 - 测量中断延迟
未学习 TI-RSLK 模块 13 - 实验视频 13.2 - 测量中断延迟
-
 未学习 TI-RSLK 模块 14 - 讲座视频 - 实时系统 - 理论
未学习 TI-RSLK 模块 14 - 讲座视频 - 实时系统 - 理论
-
 未学习 TI-RSLK 模块 14 - 讲座视频 - 实时系统 - 边沿触发中断
未学习 TI-RSLK 模块 14 - 讲座视频 - 实时系统 - 边沿触发中断
-
 未学习 TI-RSLK 模块 14 - 实验视频 14.1 - 使用边沿触发中断为碰撞开关提供实时响应
未学习 TI-RSLK 模块 14 - 实验视频 14.1 - 使用边沿触发中断为碰撞开关提供实时响应
-
 未学习 TI-RSLK 模块 15 - 讲座视频 - 数据采集系统 - 理论
未学习 TI-RSLK 模块 15 - 讲座视频 - 数据采集系统 - 理论
-
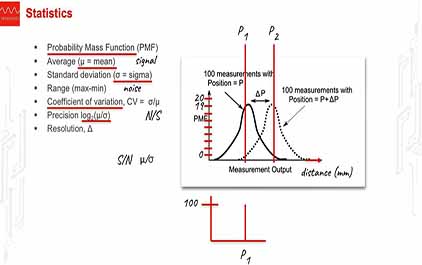 未学习 TI-RSLK 模块 15 - 讲座视频 - 数据采集系统 - 性能测量
未学习 TI-RSLK 模块 15 - 讲座视频 - 数据采集系统 - 性能测量
-
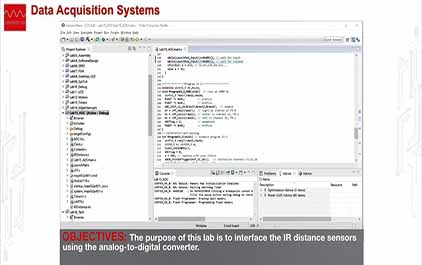 未学习 TI-RSLK 模块 15 - 实验视频 15.1 - 使用 ADC 测试红外距离测量
未学习 TI-RSLK 模块 15 - 实验视频 15.1 - 使用 ADC 测试红外距离测量
-
 未学习 TI-RSLK 模块 16 - 讲座视频 - 转速计 - 输入捕捉
未学习 TI-RSLK 模块 16 - 讲座视频 - 转速计 - 输入捕捉
-
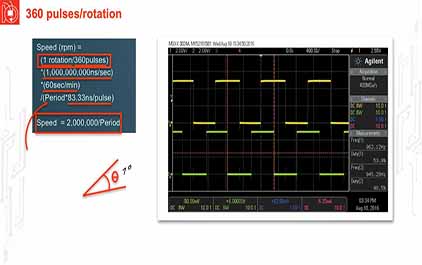 未学习 TI-RSLK 模块 16 - 讲座视频 - 转速计 - 接口
未学习 TI-RSLK 模块 16 - 讲座视频 - 转速计 - 接口
-
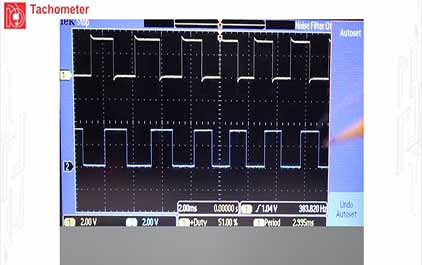 未学习 TI-RSLK 模块 16 - 实验视频 16.1 - 测试转速计以测量速度
未学习 TI-RSLK 模块 16 - 实验视频 16.1 - 测试转速计以测量速度
-
 未学习 TI-RSLK 模块 17 - 讲座视频 - 控制系统
未学习 TI-RSLK 模块 17 - 讲座视频 - 控制系统
-
 未学习 TI-RSLK 模块 17 - 实验视频 17.1 - 演示控制系统 - 积分控制
未学习 TI-RSLK 模块 17 - 实验视频 17.1 - 演示控制系统 - 积分控制
-
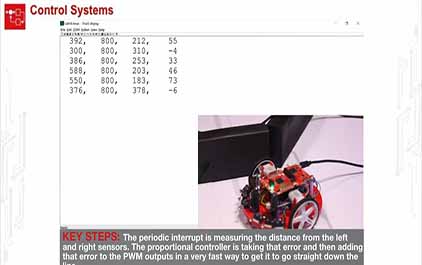 未学习 TI-RSLK 模块 17 - 实验视频 17.2 - 演示控制系统 - 比例控制
未学习 TI-RSLK 模块 17 - 实验视频 17.2 - 演示控制系统 - 比例控制
-
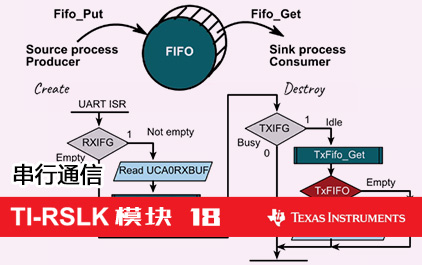 未学习 TI-RSLK 模块 18 - 讲座视频 - 串行通信 - UART
未学习 TI-RSLK 模块 18 - 讲座视频 - 串行通信 - UART
-
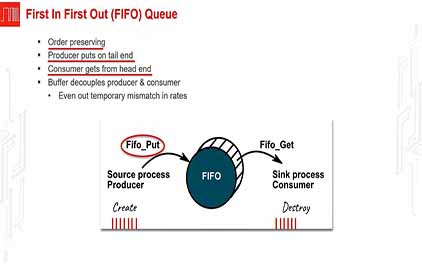 未学习 TI-RSLK 模块 18 - 讲座视频 - 串行通信 - FIFO
未学习 TI-RSLK 模块 18 - 讲座视频 - 串行通信 - FIFO
-
 未学习 TI-RSLK 模块 18 - 实验视频 18.1 - 演示 UART
未学习 TI-RSLK 模块 18 - 实验视频 18.1 - 演示 UART
-
 未学习 TI-RSLK 模块 18 - 实验视频 18.2 - 命令解释器
未学习 TI-RSLK 模块 18 - 实验视频 18.2 - 命令解释器
-
 未学习 TI-RSLK 模块 19 - 讲座视频 - 低功耗蓝牙 - 无线
未学习 TI-RSLK 模块 19 - 讲座视频 - 低功耗蓝牙 - 无线
-
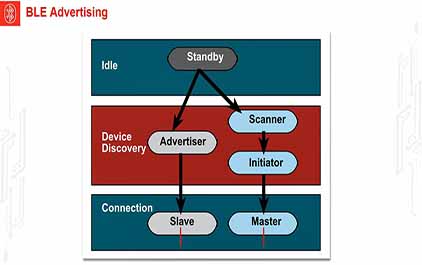 未学习 TI-RSLK 模块 19 - 讲座视频 - 低功耗蓝牙 - 理论
未学习 TI-RSLK 模块 19 - 讲座视频 - 低功耗蓝牙 - 理论
-
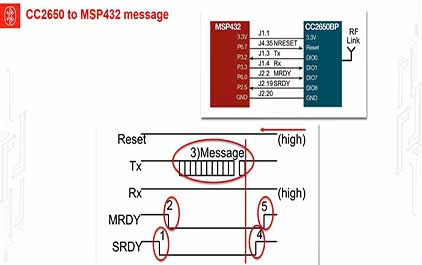 未学习 TI-RSLK 模块 19 - 讲座视频 - 低功耗蓝牙 - 简单网络处理器
未学习 TI-RSLK 模块 19 - 讲座视频 - 低功耗蓝牙 - 简单网络处理器
-
 未学习 TI-RSLK 模块 19 - 实验视频 19.1 - 演示 BLE
未学习 TI-RSLK 模块 19 - 实验视频 19.1 - 演示 BLE
-
 未学习 TI-RSLK 模块 19 - 实验视频 19.2 - 与机器人通信
未学习 TI-RSLK 模块 19 - 实验视频 19.2 - 与机器人通信





































































