mmWave SDK简介
Loading the player...
将在30s后自动为您播放下一课程
3.0 3.0还蛮行的 3.0是跟着mmwave SDK3.0 它是跟着iwr6843 在一起出来的 也就是在这个月的月初 我们现在看它到底有什么新的东西 新的东西比较有意义的 我把它用红色的线标出来了 我个人觉得比较有意义的 比如说这边,当然它这个3.0出来 为的就是要support iwr6843 它内部其实也带了1843的drivers 所以SDK3.0理论上已经可以驱动1843的板子 没有问题 然后driver有做一些update 不过这应该minor的 然后mmwaveLib它有增加一些新的东西 然后group tracker,过去的group tracker是2D 现在有3D 3D的点源 当然,最有意义的就是这种 所谓的scalable architecture 这种scalable architecture呢 它就是,它最主要要解决的问题就是 刚才讲的,在这么多应题的competition之下 在这么多应用的competition之下 我要如何做出一个有弹性的software 反馈 这个它有像DPU DPC DPIF DPM DPEDMA 那DP都是data processing的意思 那DPU就是data processing unit DPC就是data processing chain 然后有DPIF interface 还有manager 等一下我们就会慢慢看到 然后还有一些demo的改动了 另外一个很重要的 secondary的bootloader 如果你要量产产品的话 secondary bootloader一定不可少 因为你终究要做产品 要做[听不清]的update 那这个一定是要在secondary bootloader 那为什么把它叫secondary bootloader 因为我们第一个BootLoader就是bootl bootl已经消失在IC里面 已经没办法改了 bootl所有的[听不清]和IC 开始都是bootl先执行 执行完之后 控制权就会交到使用者的application 那使用者的第一次application是 在传统上应该就是 我们把它叫做secondary bootloader secondary bootloader要做什么事 就是 更新分类 还有做一大堆你想要的事 比如说你搞不好想要在里面做一些产测 你要做一些产测的流程 你要做一些其他的东西 反正你爱怎么写就怎么写 secondary bootloader 我们TI其实也蛮贴心的 据我所知 没有一家其他的 像其他secondary BootLoader大概都要自己写 其实这个一般来说都要自己写 不应该是[听不清]来帮你写 为什么呢 因为secondary bootloader就是代表你的一些产线 产测等等流程 你要怎么update你的分类等等的 这种事实上都是非常customize的东西 非常customize的software 但是我们有写一个sample 所以你看这个 应该就可以写出自己的secondary BootLoader 这样会加速你的开发进度 好 那3.0的architecture呢 回到刚刚的主题 3.0的architecture到底跟过去的二点多有什么不同 首先 过去的SDK 一点多 二点多 它的处理链事实上是跟你的mmWave demo是捆在一起的 换句话说 你的application跟你的chain是混在一起的 那这样有什么缺点 有什么缺点 等于说你今天就没有办法 一直reuse这字的东西 没有办法一直reuse这样子的东西 所以我们现在要做的呢 首先呢 我们要把chain 从application把它分离出来 把它抽出来 让它更独立 更独立有很多好处 就代表说 你以后工业可能有成千上百的应用 比如说像现在就有people counting 有做空间占据的一些等等的 可能未来还有更多的应用 每个应用的chain可能就长得不一样 所以说你以后只要抽换掉这些chain就可以了 就不像过去 因为两个已经搅和在一起 就很难 你就等于全部UR这边就要重写就是了 我们的想法就是说 以后你可以抽换这个chain 可以抽换这个chain 这个chain就是 DPC 我们刚刚提到的 data processing chain DPC呢 我们可以把它想象成一条工厂的生产线 每条生产线上面就有很多机台 对不对 每一个机台就是一个DPU 好不好 所以这样是不是很简单 所以一个chain里面就有很多DPU 每个DPU就去做它的事情 每个DPU就去做它的事情 比如说 你今天要做range的FFT 就会有个range的FFT的DPU 你今天要做CFAR的 CFAR的那个...... 部分 就会有一个CFAR的DPU 类似这样子 好 好 所以这个是第一个 你可以看到这样的改变 好 那接着呢 橘色这边框出来的都是有改变的部分 有改变的部分 更细节的改变是包含了 比如说 因为在雷达这边 我们理解到就是说 有些客户对[听不清] 尤其是一些工业的那个 客户对[听不清]事实上不熟悉的 那你必须要引进一些third party 对吧 那可是如果像过去的那种 那种application跟整个处理链全部混在一起的话 其实对third party而言 [听不清]的third party或provider而言 他们会变得很麻烦 没有办法跟你的application切割开来 所以我们希望的是 像一些third party 它能够直接提供产线的机台 make sense吗 好 就是说 你可以 你可以 比如说你今天 一个[听不清]的third party就 create自己的DPU 然后这个DPU就可以被plug in到整个chain里面的一部分 所以这样的话也可能达成就是说 对这种third party而言 他们以后就好办事 好办事 对 DPIF 这个东西很妙 如果你去trace call的话 没有[听不清] 它就是纯粹的一些 资料结构的DH档 讲白了 这个部分呢 都是在讲一些 DPIF都是在讲一些 在整个链里面 一定都会伴随着 资料 这些资料包含了像 ADC buffer 像这边提到的 或者雷达cube 或者detection metrics 等等的 这个就是data path interface DPIF 然后 data path manager DPM DPM事实上就是来管理 管理DPC的 所以如果你去看DPM的 在做一些 initialization的时候就会发觉 DPM initialize的时候 它就会去指定说你今天要去挂哪一条 把哪一条链给挂上去 就呼应了我刚才的讲法 你今天不同应用可能就要挂上不一样的链 所以它的设计哲学就变得不太一样 每条链的DPU都是可以独立的 好 这个就是刚刚讲的 scalable chain concept 就是我刚才讲的 因为你会有不同的HWA 你可能要走HWA或者是DSP 所以你必须要这种 它就是 像这个 就是range的DPU range的FFTE以后可能在HWA service做 也有可能在DSP做 所以你的DPU你就会准备 准备两种 对 DPU就会准备两种 那这个雷达cube的 这些format 像这个 你要 知道它的格式的长相就是 从 DPIF就可以去看到雷达cube的长相 大体上是这样子 我觉得这个设计的方向是非常正确的 只不过 如果从软体的角度来看 其实这个是比较不容易了解 因为过去就是 一条线通到底 刚才我看mmWave demo application 我就一路看到底 它整个流程大概就知道了 但是它现在把它抽象化以后 就是 就变成一个模组这样子 从软体工程的角度来看是对的 但是 读上面会比较复杂一点 好 那这也是刚才有提过的 DPM DPM可以挂不同的DPC DPC是由各式各样的DPU组成 所以以后各位的程式里面 可能可以准备 很多条DPC 每条DPC都可以准备不同的DPU DPU当然就是有些可以共用 有些不能共用 来保持它的弹性 大体上就是这样子的部分 那DPEDMA 这个就没什么 我想大概也不会有人要去改它 反正DEMA都是搬资料 这种东西大概不会有人要去改它 好 会去动的 我觉得就是 DPU 就说 嗯 因为你们都会有自己的 想要做的 algorithm 所以你也可以create自己的DPU 然后插到整个链里面去 好 那这个是我刚才讲的 你看这张图要表达就是 它想把application开发者跟algorithm processing chain的开发者要去把它分开来 去把它分开来 要去做这样的事情 OK 这是DPIF DPIF就是ADC的雷达cube 这些电云 好 然后DPU它的function code大概都是这种样子 init config process control还有deinit 那当然了 主要的流程一定都是写在 process 这边 做process之前 要先config 对 好 然后 因为 我这边还有用红色的框起来 所有的memory location for io buffer 好 是在DPU 外面去allocate DPU本身 DPU本身并不去挖memory 为什么会这样子 是因为 其实 其实memory有限 再加上 整条链的流程里面 其实有很多的 资料是要共享的 如果每个DPU都去挖自己的 就会有点你也挖我也挖 就资源浪费 因为它 像雷达cube 它可能有两个DPU都要同时access雷达cube 对吧 好 是这样子的原因 好 这个是data processing chain callback function等等 OK 那它的 目录的架构 你看 也跟过去长得不太一样 过去我想 control这边 control这边还是有啦 好像就是mmWave DPM这边 然后 datapath 目前主要的呢 以后要看的可能最主要的就要落在 TI下面datapath这个目录下面 这个demo是属于application mmWave Demo这种东西 因为它的处理链已经被抽出来了 所以 这个理论上来讲 size会变小 然后这边 被抽出来的部分都会被放到 比如说像 DPC DPC里面 或者是DPU下面 这边 比如说这边就有一个range的 DPU 然后这个DPC下面又 挂各式各样的 像dopplerproc 或者是AOA的 DPU的 就挂住这边 然后 这个是objectdetection 目前我们挂上去的DPC就是objectdetection 如果以后你要做自己的链的话 很明显的你就是在这边再create一个folder 叫自己的一个名字 然后 就去调用这些DPU 各式各样的DPU 来使用 所以我觉得这个逻辑上就 蛮make sense的 这样也可以解决到时候 我们刚才提到的那些问题 还蛮不错的 只不过对过去熟悉1.0和2.0的人 就比较辛苦一点 要重新 重新思考这样子的架构 好 DPU DPU 像刚刚的cluster removal 把静止的移除的那种 DPU就放在这边 每个DPU到时候都会有source code 还有document 那document当然还是用doc doc那种东西所存在的 好 我想call flow我们就不用再一个一个过了 这种call flow在mmWave SDK3.0的概念里面 其实就有画出来 大家就去看一看 基本上就是 是怎么样 调用它 DPM怎么样调用DPC DPC怎么样调用DPU 大概就是这样子 所以我是觉得还好 还好 好 那这个 我想我们 时间也好像也有点超过了 我是不知道能超过多久 但是 像这些东西 其实要讲可以讲很久 我们今天时间不是那么充足 像这个各式各样的DPU的介绍 介绍 好 好 那 我觉得就是只要掌握基本原理的话 就比较容易看得懂 看得懂它背后的思维到底是什么 那这个每个DPU我就不去过它 那我最后再讲一个 这个3.0 我最后再讲一个 memory 这个是based on mmWave SDK 1.多2.多 那样子的长相 我自己 因为挖memory一向都是很重要的 课题 尤其是我们的memory 都是设计得蛮刚好 我觉得哈 真的还蛮厉害的 每次都设计得刚刚好 在margin边缘 好 这个是1642的 1642的memory的部分 你可以看到有这么多块吗 那我把 这边全部加在一起 就是刚才讲到的1.5Megabit 那雷达的cube都是放在这边 雷达的cube放在这边 影响到我们的 像过去 如果你是挖memory的话 挖memory的话 过去mmWave SKD 还蛮简单的 各位有注意到这边吗 这边有一个function code 在mmWave SDK 里面 这个function code datapath的config buffer 这个function code里面 事实上就是去负责去 你就会看到里面有呼叫很多 memory location的function 那那些memory location的function 就去负责挖这些所有记忆体的配置 那我们先从L3这边看起 L3这边有几个buffer是放在L3这边 最重要的当然就是雷达cube了 然后还有一些ADC的data buffer等等 那这边我写好一些试算表 就是说你只要输入你今天range FFT是多少 doppler FFT是多少 有多少T多少R对不对 你就可以 计算出 memory cube的size要多大 像因为我们刚刚看到 L3的memory 大概只有768k 所以我们的目前的配置 比如说以164 它是一个 二梯式这样的一个 架构之下 我们的配置大概就是25664 mmWave demo 它用的 配置也是25664这样子的配置 我们比较特别的 就是里面每一个element 都是complex 刚刚不是有提到 real的base band跟complex的base band吗 好 因为我们是使用complex的base band 所以它每个资料形态全部都是complex 每个complex都是带有实数部跟虚数部 然后都是4个bit 都是4个bit 所以呢 这边 是它的公式 就是说雷达cube是用什么样的方式 在做memory location的 好 我做这个表 反正我就是直接看source code 它memory location怎么样挖 它是base on什么样条件去挖 我就把它条件写在这边 所以就可以算得出来 然后这个可以搭配这个一起看 我想这个流程图 这个流程图是 mmWave demo的流程图 我这边就把一些注解上去 我把它注解上去 它是怎么样去挖的 那这个要花一点时间去理解 因为这个东西不是这么好理解 然后我们 那个demo的[听不清]的打法是这种样子 如果你是1642mmWave demo的话 那它的 它是 Tx1 先打一个chirp 1 接着换一个Tx2 打一个chirp 2 这样子 它的设定 原来设定是这样子 好 这个chirp1 chirp2 到时候 Rx回来的时候 它就是 这一列就是Tx1 的资料 然后这个是Tx2的资料 等等 好 这样子 那当然这个都是 其实这个都 是资料搬来搬去 交错来交错去 这种要花一点时间理解 其实这个图还蛮重要的 好 那我想 我们在mmWave SDK 这边大概就先暂时讲到这边 那还有一些东西的话 可能在下午的 如果有时间的话我们再继续讲 因为我还想讲的包含了 比如说chirp chirp的一些 设定 还有像advanced[听不清]的设定 advanced[听不清]的一些设定 那这个都还蛮关键的 都还蛮关键的 好 那我们就先讲到这里
3.0 3.0还蛮行的 3.0是跟着mmwave SDK3.0 它是跟着iwr6843 在一起出来的 也就是在这个月的月初 我们现在看它到底有什么新的东西 新的东西比较有意义的 我把它用红色的线标出来了 我个人觉得比较有意义的 比如说这边,当然它这个3.0出来 为的就是要support iwr6843 它内部其实也带了1843的drivers 所以SDK3.0理论上已经可以驱动1843的板子 没有问题 然后driver有做一些update 不过这应该minor的 然后mmwaveLib它有增加一些新的东西 然后group tracker,过去的group tracker是2D 现在有3D 3D的点源 当然,最有意义的就是这种 所谓的scalable architecture 这种scalable architecture呢 它就是,它最主要要解决的问题就是 刚才讲的,在这么多应题的competition之下 在这么多应用的competition之下 我要如何做出一个有弹性的software 反馈 这个它有像DPU DPC DPIF DPM DPEDMA 那DP都是data processing的意思 那DPU就是data processing unit DPC就是data processing chain 然后有DPIF interface 还有manager 等一下我们就会慢慢看到 然后还有一些demo的改动了 另外一个很重要的 secondary的bootloader 如果你要量产产品的话 secondary bootloader一定不可少 因为你终究要做产品 要做[听不清]的update 那这个一定是要在secondary bootloader 那为什么把它叫secondary bootloader 因为我们第一个BootLoader就是bootl bootl已经消失在IC里面 已经没办法改了 bootl所有的[听不清]和IC 开始都是bootl先执行 执行完之后 控制权就会交到使用者的application 那使用者的第一次application是 在传统上应该就是 我们把它叫做secondary bootloader secondary bootloader要做什么事 就是 更新分类 还有做一大堆你想要的事 比如说你搞不好想要在里面做一些产测 你要做一些产测的流程 你要做一些其他的东西 反正你爱怎么写就怎么写 secondary bootloader 我们TI其实也蛮贴心的 据我所知 没有一家其他的 像其他secondary BootLoader大概都要自己写 其实这个一般来说都要自己写 不应该是[听不清]来帮你写 为什么呢 因为secondary bootloader就是代表你的一些产线 产测等等流程 你要怎么update你的分类等等的 这种事实上都是非常customize的东西 非常customize的software 但是我们有写一个sample 所以你看这个 应该就可以写出自己的secondary BootLoader 这样会加速你的开发进度 好 那3.0的architecture呢 回到刚刚的主题 3.0的architecture到底跟过去的二点多有什么不同 首先 过去的SDK 一点多 二点多 它的处理链事实上是跟你的mmWave demo是捆在一起的 换句话说 你的application跟你的chain是混在一起的 那这样有什么缺点 有什么缺点 等于说你今天就没有办法 一直reuse这字的东西 没有办法一直reuse这样子的东西 所以我们现在要做的呢 首先呢 我们要把chain 从application把它分离出来 把它抽出来 让它更独立 更独立有很多好处 就代表说 你以后工业可能有成千上百的应用 比如说像现在就有people counting 有做空间占据的一些等等的 可能未来还有更多的应用 每个应用的chain可能就长得不一样 所以说你以后只要抽换掉这些chain就可以了 就不像过去 因为两个已经搅和在一起 就很难 你就等于全部UR这边就要重写就是了 我们的想法就是说 以后你可以抽换这个chain 可以抽换这个chain 这个chain就是 DPC 我们刚刚提到的 data processing chain DPC呢 我们可以把它想象成一条工厂的生产线 每条生产线上面就有很多机台 对不对 每一个机台就是一个DPU 好不好 所以这样是不是很简单 所以一个chain里面就有很多DPU 每个DPU就去做它的事情 每个DPU就去做它的事情 比如说 你今天要做range的FFT 就会有个range的FFT的DPU 你今天要做CFAR的 CFAR的那个...... 部分 就会有一个CFAR的DPU 类似这样子 好 好 所以这个是第一个 你可以看到这样的改变 好 那接着呢 橘色这边框出来的都是有改变的部分 有改变的部分 更细节的改变是包含了 比如说 因为在雷达这边 我们理解到就是说 有些客户对[听不清] 尤其是一些工业的那个 客户对[听不清]事实上不熟悉的 那你必须要引进一些third party 对吧 那可是如果像过去的那种 那种application跟整个处理链全部混在一起的话 其实对third party而言 [听不清]的third party或provider而言 他们会变得很麻烦 没有办法跟你的application切割开来 所以我们希望的是 像一些third party 它能够直接提供产线的机台 make sense吗 好 就是说 你可以 你可以 比如说你今天 一个[听不清]的third party就 create自己的DPU 然后这个DPU就可以被plug in到整个chain里面的一部分 所以这样的话也可能达成就是说 对这种third party而言 他们以后就好办事 好办事 对 DPIF 这个东西很妙 如果你去trace call的话 没有[听不清] 它就是纯粹的一些 资料结构的DH档 讲白了 这个部分呢 都是在讲一些 DPIF都是在讲一些 在整个链里面 一定都会伴随着 资料 这些资料包含了像 ADC buffer 像这边提到的 或者雷达cube 或者detection metrics 等等的 这个就是data path interface DPIF 然后 data path manager DPM DPM事实上就是来管理 管理DPC的 所以如果你去看DPM的 在做一些 initialization的时候就会发觉 DPM initialize的时候 它就会去指定说你今天要去挂哪一条 把哪一条链给挂上去 就呼应了我刚才的讲法 你今天不同应用可能就要挂上不一样的链 所以它的设计哲学就变得不太一样 每条链的DPU都是可以独立的 好 这个就是刚刚讲的 scalable chain concept 就是我刚才讲的 因为你会有不同的HWA 你可能要走HWA或者是DSP 所以你必须要这种 它就是 像这个 就是range的DPU range的FFTE以后可能在HWA service做 也有可能在DSP做 所以你的DPU你就会准备 准备两种 对 DPU就会准备两种 那这个雷达cube的 这些format 像这个 你要 知道它的格式的长相就是 从 DPIF就可以去看到雷达cube的长相 大体上是这样子 我觉得这个设计的方向是非常正确的 只不过 如果从软体的角度来看 其实这个是比较不容易了解 因为过去就是 一条线通到底 刚才我看mmWave demo application 我就一路看到底 它整个流程大概就知道了 但是它现在把它抽象化以后 就是 就变成一个模组这样子 从软体工程的角度来看是对的 但是 读上面会比较复杂一点 好 那这也是刚才有提过的 DPM DPM可以挂不同的DPC DPC是由各式各样的DPU组成 所以以后各位的程式里面 可能可以准备 很多条DPC 每条DPC都可以准备不同的DPU DPU当然就是有些可以共用 有些不能共用 来保持它的弹性 大体上就是这样子的部分 那DPEDMA 这个就没什么 我想大概也不会有人要去改它 反正DEMA都是搬资料 这种东西大概不会有人要去改它 好 会去动的 我觉得就是 DPU 就说 嗯 因为你们都会有自己的 想要做的 algorithm 所以你也可以create自己的DPU 然后插到整个链里面去 好 那这个是我刚才讲的 你看这张图要表达就是 它想把application开发者跟algorithm processing chain的开发者要去把它分开来 去把它分开来 要去做这样的事情 OK 这是DPIF DPIF就是ADC的雷达cube 这些电云 好 然后DPU它的function code大概都是这种样子 init config process control还有deinit 那当然了 主要的流程一定都是写在 process 这边 做process之前 要先config 对 好 然后 因为 我这边还有用红色的框起来 所有的memory location for io buffer 好 是在DPU 外面去allocate DPU本身 DPU本身并不去挖memory 为什么会这样子 是因为 其实 其实memory有限 再加上 整条链的流程里面 其实有很多的 资料是要共享的 如果每个DPU都去挖自己的 就会有点你也挖我也挖 就资源浪费 因为它 像雷达cube 它可能有两个DPU都要同时access雷达cube 对吧 好 是这样子的原因 好 这个是data processing chain callback function等等 OK 那它的 目录的架构 你看 也跟过去长得不太一样 过去我想 control这边 control这边还是有啦 好像就是mmWave DPM这边 然后 datapath 目前主要的呢 以后要看的可能最主要的就要落在 TI下面datapath这个目录下面 这个demo是属于application mmWave Demo这种东西 因为它的处理链已经被抽出来了 所以 这个理论上来讲 size会变小 然后这边 被抽出来的部分都会被放到 比如说像 DPC DPC里面 或者是DPU下面 这边 比如说这边就有一个range的 DPU 然后这个DPC下面又 挂各式各样的 像dopplerproc 或者是AOA的 DPU的 就挂住这边 然后 这个是objectdetection 目前我们挂上去的DPC就是objectdetection 如果以后你要做自己的链的话 很明显的你就是在这边再create一个folder 叫自己的一个名字 然后 就去调用这些DPU 各式各样的DPU 来使用 所以我觉得这个逻辑上就 蛮make sense的 这样也可以解决到时候 我们刚才提到的那些问题 还蛮不错的 只不过对过去熟悉1.0和2.0的人 就比较辛苦一点 要重新 重新思考这样子的架构 好 DPU DPU 像刚刚的cluster removal 把静止的移除的那种 DPU就放在这边 每个DPU到时候都会有source code 还有document 那document当然还是用doc doc那种东西所存在的 好 我想call flow我们就不用再一个一个过了 这种call flow在mmWave SDK3.0的概念里面 其实就有画出来 大家就去看一看 基本上就是 是怎么样 调用它 DPM怎么样调用DPC DPC怎么样调用DPU 大概就是这样子 所以我是觉得还好 还好 好 那这个 我想我们 时间也好像也有点超过了 我是不知道能超过多久 但是 像这些东西 其实要讲可以讲很久 我们今天时间不是那么充足 像这个各式各样的DPU的介绍 介绍 好 好 那 我觉得就是只要掌握基本原理的话 就比较容易看得懂 看得懂它背后的思维到底是什么 那这个每个DPU我就不去过它 那我最后再讲一个 这个3.0 我最后再讲一个 memory 这个是based on mmWave SDK 1.多2.多 那样子的长相 我自己 因为挖memory一向都是很重要的 课题 尤其是我们的memory 都是设计得蛮刚好 我觉得哈 真的还蛮厉害的 每次都设计得刚刚好 在margin边缘 好 这个是1642的 1642的memory的部分 你可以看到有这么多块吗 那我把 这边全部加在一起 就是刚才讲到的1.5Megabit 那雷达的cube都是放在这边 雷达的cube放在这边 影响到我们的 像过去 如果你是挖memory的话 挖memory的话 过去mmWave SKD 还蛮简单的 各位有注意到这边吗 这边有一个function code 在mmWave SDK 里面 这个function code datapath的config buffer 这个function code里面 事实上就是去负责去 你就会看到里面有呼叫很多 memory location的function 那那些memory location的function 就去负责挖这些所有记忆体的配置 那我们先从L3这边看起 L3这边有几个buffer是放在L3这边 最重要的当然就是雷达cube了 然后还有一些ADC的data buffer等等 那这边我写好一些试算表 就是说你只要输入你今天range FFT是多少 doppler FFT是多少 有多少T多少R对不对 你就可以 计算出 memory cube的size要多大 像因为我们刚刚看到 L3的memory 大概只有768k 所以我们的目前的配置 比如说以164 它是一个 二梯式这样的一个 架构之下 我们的配置大概就是25664 mmWave demo 它用的 配置也是25664这样子的配置 我们比较特别的 就是里面每一个element 都是complex 刚刚不是有提到 real的base band跟complex的base band吗 好 因为我们是使用complex的base band 所以它每个资料形态全部都是complex 每个complex都是带有实数部跟虚数部 然后都是4个bit 都是4个bit 所以呢 这边 是它的公式 就是说雷达cube是用什么样的方式 在做memory location的 好 我做这个表 反正我就是直接看source code 它memory location怎么样挖 它是base on什么样条件去挖 我就把它条件写在这边 所以就可以算得出来 然后这个可以搭配这个一起看 我想这个流程图 这个流程图是 mmWave demo的流程图 我这边就把一些注解上去 我把它注解上去 它是怎么样去挖的 那这个要花一点时间去理解 因为这个东西不是这么好理解 然后我们 那个demo的[听不清]的打法是这种样子 如果你是1642mmWave demo的话 那它的 它是 Tx1 先打一个chirp 1 接着换一个Tx2 打一个chirp 2 这样子 它的设定 原来设定是这样子 好 这个chirp1 chirp2 到时候 Rx回来的时候 它就是 这一列就是Tx1 的资料 然后这个是Tx2的资料 等等 好 这样子 那当然这个都是 其实这个都 是资料搬来搬去 交错来交错去 这种要花一点时间理解 其实这个图还蛮重要的 好 那我想 我们在mmWave SDK 这边大概就先暂时讲到这边 那还有一些东西的话 可能在下午的 如果有时间的话我们再继续讲 因为我还想讲的包含了 比如说chirp chirp的一些 设定 还有像advanced[听不清]的设定 advanced[听不清]的一些设定 那这个都还蛮关键的 都还蛮关键的 好 那我们就先讲到这里
3.0 3.0还蛮行的
3.0是跟着mmwave SDK3.0
它是跟着iwr6843
在一起出来的
也就是在这个月的月初
我们现在看它到底有什么新的东西
新的东西比较有意义的
我把它用红色的线标出来了
我个人觉得比较有意义的
比如说这边,当然它这个3.0出来
为的就是要support iwr6843
它内部其实也带了1843的drivers
所以SDK3.0理论上已经可以驱动1843的板子
没有问题
然后driver有做一些update
不过这应该minor的
然后mmwaveLib它有增加一些新的东西
然后group tracker,过去的group tracker是2D
现在有3D
3D的点源
当然,最有意义的就是这种
所谓的scalable architecture
这种scalable architecture呢
它就是,它最主要要解决的问题就是
刚才讲的,在这么多应题的competition之下
在这么多应用的competition之下
我要如何做出一个有弹性的software 反馈
这个它有像DPU DPC DPIF DPM
DPEDMA
那DP都是data processing的意思
那DPU就是data processing unit
DPC就是data processing chain
然后有DPIF interface 还有manager
等一下我们就会慢慢看到
然后还有一些demo的改动了 另外一个很重要的
secondary的bootloader
如果你要量产产品的话
secondary bootloader一定不可少
因为你终究要做产品 要做[听不清]的update
那这个一定是要在secondary bootloader
那为什么把它叫secondary bootloader
因为我们第一个BootLoader就是bootl
bootl已经消失在IC里面
已经没办法改了
bootl所有的[听不清]和IC
开始都是bootl先执行
执行完之后 控制权就会交到使用者的application
那使用者的第一次application是
在传统上应该就是
我们把它叫做secondary bootloader
secondary bootloader要做什么事 就是
更新分类 还有做一大堆你想要的事
比如说你搞不好想要在里面做一些产测
你要做一些产测的流程 你要做一些其他的东西
反正你爱怎么写就怎么写
secondary bootloader
我们TI其实也蛮贴心的
据我所知 没有一家其他的
像其他secondary BootLoader大概都要自己写
其实这个一般来说都要自己写
不应该是[听不清]来帮你写 为什么呢
因为secondary bootloader就是代表你的一些产线 产测等等流程
你要怎么update你的分类等等的
这种事实上都是非常customize的东西
非常customize的software
但是我们有写一个sample
所以你看这个 应该就可以写出自己的secondary BootLoader
这样会加速你的开发进度
好 那3.0的architecture呢 回到刚刚的主题
3.0的architecture到底跟过去的二点多有什么不同
首先 过去的SDK 一点多 二点多
它的处理链事实上是跟你的mmWave demo是捆在一起的
换句话说 你的application跟你的chain是混在一起的
那这样有什么缺点
有什么缺点 等于说你今天就没有办法
一直reuse这字的东西
没有办法一直reuse这样子的东西
所以我们现在要做的呢 首先呢 我们要把chain
从application把它分离出来
把它抽出来
让它更独立
更独立有很多好处
就代表说 你以后工业可能有成千上百的应用
比如说像现在就有people counting
有做空间占据的一些等等的
可能未来还有更多的应用
每个应用的chain可能就长得不一样
所以说你以后只要抽换掉这些chain就可以了
就不像过去 因为两个已经搅和在一起
就很难 你就等于全部UR这边就要重写就是了
我们的想法就是说
以后你可以抽换这个chain
可以抽换这个chain 这个chain就是
DPC 我们刚刚提到的 data processing chain
DPC呢 我们可以把它想象成一条工厂的生产线
每条生产线上面就有很多机台 对不对
每一个机台就是一个DPU
好不好 所以这样是不是很简单
所以一个chain里面就有很多DPU
每个DPU就去做它的事情
每个DPU就去做它的事情
比如说 你今天要做range的FFT
就会有个range的FFT的DPU
你今天要做CFAR的 CFAR的那个......
部分 就会有一个CFAR的DPU
类似这样子
好 好 所以这个是第一个 你可以看到这样的改变
好 那接着呢
橘色这边框出来的都是有改变的部分
有改变的部分 更细节的改变是包含了 比如说
因为在雷达这边 我们理解到就是说
有些客户对[听不清] 尤其是一些工业的那个
客户对[听不清]事实上不熟悉的
那你必须要引进一些third party
对吧 那可是如果像过去的那种
那种application跟整个处理链全部混在一起的话
其实对third party而言 [听不清]的third party或provider而言
他们会变得很麻烦 没有办法跟你的application切割开来
所以我们希望的是 像一些third party
它能够直接提供产线的机台
make sense吗 好 就是说 你可以
你可以 比如说你今天 一个[听不清]的third party就
create自己的DPU
然后这个DPU就可以被plug in到整个chain里面的一部分
所以这样的话也可能达成就是说
对这种third party而言 他们以后就好办事
好办事 对
DPIF 这个东西很妙
如果你去trace call的话
没有[听不清] 它就是纯粹的一些
资料结构的DH档
讲白了 这个部分呢
都是在讲一些 DPIF都是在讲一些
在整个链里面 一定都会伴随着
资料 这些资料包含了像
ADC buffer 像这边提到的
或者雷达cube
或者detection metrics
等等的 这个就是data path interface DPIF
然后 data path manager
DPM DPM事实上就是来管理
管理DPC的 所以如果你去看DPM的 在做一些
initialization的时候就会发觉 DPM initialize的时候
它就会去指定说你今天要去挂哪一条
把哪一条链给挂上去
就呼应了我刚才的讲法
你今天不同应用可能就要挂上不一样的链
所以它的设计哲学就变得不太一样
每条链的DPU都是可以独立的
好 这个就是刚刚讲的
scalable chain concept 就是我刚才讲的
因为你会有不同的HWA
你可能要走HWA或者是DSP
所以你必须要这种 它就是
像这个 就是range的DPU
range的FFTE以后可能在HWA service做
也有可能在DSP做
所以你的DPU你就会准备
准备两种
对 DPU就会准备两种
那这个雷达cube的
这些format 像这个 你要
知道它的格式的长相就是
从 DPIF就可以去看到雷达cube的长相
大体上是这样子
我觉得这个设计的方向是非常正确的
只不过 如果从软体的角度来看
其实这个是比较不容易了解 因为过去就是
一条线通到底 刚才我看mmWave demo
application 我就一路看到底
它整个流程大概就知道了
但是它现在把它抽象化以后 就是
就变成一个模组这样子
从软体工程的角度来看是对的
但是 读上面会比较复杂一点 好
那这也是刚才有提过的 DPM
DPM可以挂不同的DPC
DPC是由各式各样的DPU组成
所以以后各位的程式里面 可能可以准备
很多条DPC 每条DPC都可以准备不同的DPU
DPU当然就是有些可以共用 有些不能共用
来保持它的弹性
大体上就是这样子的部分
那DPEDMA 这个就没什么 我想大概也不会有人要去改它
反正DEMA都是搬资料
这种东西大概不会有人要去改它
好 会去动的 我觉得就是
DPU 就说 嗯
因为你们都会有自己的 想要做的
algorithm 所以你也可以create自己的DPU
然后插到整个链里面去
好 那这个是我刚才讲的
你看这张图要表达就是
它想把application开发者跟algorithm
processing chain的开发者要去把它分开来
去把它分开来
要去做这样的事情
OK
这是DPIF
DPIF就是ADC的雷达cube 这些电云
好
然后DPU它的function code大概都是这种样子
init config process control还有deinit
那当然了 主要的流程一定都是写在
process 这边
做process之前 要先config
对 好
然后 因为 我这边还有用红色的框起来
所有的memory location for io buffer
好 是在DPU
外面去allocate
DPU本身
DPU本身并不去挖memory 为什么会这样子 是因为
其实
其实memory有限 再加上
整条链的流程里面 其实有很多的
资料是要共享的 如果每个DPU都去挖自己的
就会有点你也挖我也挖 就资源浪费
因为它 像雷达cube
它可能有两个DPU都要同时access雷达cube
对吧 好 是这样子的原因
好 这个是data processing chain
callback function等等
OK 那它的
目录的架构 你看
也跟过去长得不太一样
过去我想 control这边
control这边还是有啦 好像就是mmWave
DPM这边 然后
datapath 目前主要的呢
以后要看的可能最主要的就要落在
TI下面datapath这个目录下面
这个demo是属于application
mmWave Demo这种东西
因为它的处理链已经被抽出来了 所以
这个理论上来讲 size会变小
然后这边 被抽出来的部分都会被放到
比如说像 DPC
DPC里面
或者是DPU下面
这边 比如说这边就有一个range的
DPU 然后这个DPC下面又
挂各式各样的 像dopplerproc
或者是AOA的 DPU的 就挂住这边
然后 这个是objectdetection
目前我们挂上去的DPC就是objectdetection
如果以后你要做自己的链的话
很明显的你就是在这边再create一个folder
叫自己的一个名字
然后 就去调用这些DPU 各式各样的DPU
来使用 所以我觉得这个逻辑上就
蛮make sense的
这样也可以解决到时候 我们刚才提到的那些问题
还蛮不错的
只不过对过去熟悉1.0和2.0的人
就比较辛苦一点 要重新
重新思考这样子的架构
好 DPU DPU
像刚刚的cluster removal
把静止的移除的那种
DPU就放在这边
每个DPU到时候都会有source code
还有document 那document当然还是用doc
doc那种东西所存在的
好 我想call flow我们就不用再一个一个过了
这种call flow在mmWave SDK3.0的概念里面
其实就有画出来
大家就去看一看 基本上就是
是怎么样 调用它 DPM怎么样调用DPC
DPC怎么样调用DPU
大概就是这样子 所以我是觉得还好
还好 好 那这个 我想我们
时间也好像也有点超过了
我是不知道能超过多久 但是
像这些东西
其实要讲可以讲很久 我们今天时间不是那么充足
像这个各式各样的DPU的介绍
介绍 好
好 那 我觉得就是只要掌握基本原理的话
就比较容易看得懂
看得懂它背后的思维到底是什么
那这个每个DPU我就不去过它
那我最后再讲一个
这个3.0 我最后再讲一个
memory
这个是based on mmWave SDK 1.多2.多
那样子的长相
我自己 因为挖memory一向都是很重要的
课题 尤其是我们的memory
都是设计得蛮刚好 我觉得哈
真的还蛮厉害的
每次都设计得刚刚好 在margin边缘
好
这个是1642的
1642的memory的部分
你可以看到有这么多块吗
那我把 这边全部加在一起
就是刚才讲到的1.5Megabit
那雷达的cube都是放在这边
雷达的cube放在这边
影响到我们的 像过去
如果你是挖memory的话
挖memory的话
过去mmWave SKD
还蛮简单的 各位有注意到这边吗
这边有一个function code
在mmWave SDK
里面 这个function code datapath的config buffer
这个function code里面
事实上就是去负责去 你就会看到里面有呼叫很多
memory location的function
那那些memory location的function
就去负责挖这些所有记忆体的配置
那我们先从L3这边看起
L3这边有几个buffer是放在L3这边
最重要的当然就是雷达cube了
然后还有一些ADC的data buffer等等
那这边我写好一些试算表
就是说你只要输入你今天range FFT是多少
doppler FFT是多少
有多少T多少R对不对 你就可以
计算出 memory cube的size要多大
像因为我们刚刚看到 L3的memory
大概只有768k
所以我们的目前的配置
比如说以164 它是一个
二梯式这样的一个
架构之下 我们的配置大概就是25664
mmWave demo 它用的
配置也是25664这样子的配置
我们比较特别的 就是里面每一个element
都是complex 刚刚不是有提到
real的base band跟complex的base band吗
好 因为我们是使用complex的base band
所以它每个资料形态全部都是complex
每个complex都是带有实数部跟虚数部
然后都是4个bit
都是4个bit 所以呢 这边
是它的公式
就是说雷达cube是用什么样的方式
在做memory location的
好 我做这个表 反正我就是直接看source code
它memory location怎么样挖
它是base on什么样条件去挖 我就把它条件写在这边
所以就可以算得出来
然后这个可以搭配这个一起看
我想这个流程图 这个流程图是
mmWave demo的流程图
我这边就把一些注解上去
我把它注解上去
它是怎么样去挖的
那这个要花一点时间去理解
因为这个东西不是这么好理解 然后我们
那个demo的[听不清]的打法是这种样子
如果你是1642mmWave demo的话
那它的 它是
Tx1 先打一个chirp 1 接着换一个Tx2
打一个chirp 2 这样子
它的设定 原来设定是这样子
好 这个chirp1 chirp2 到时候
Rx回来的时候
它就是 这一列就是Tx1
的资料
然后这个是Tx2的资料 等等
好 这样子
那当然这个都是 其实这个都
是资料搬来搬去
交错来交错去
这种要花一点时间理解
其实这个图还蛮重要的
好 那我想
我们在mmWave SDK
这边大概就先暂时讲到这边
那还有一些东西的话 可能在下午的
如果有时间的话我们再继续讲
因为我还想讲的包含了
比如说chirp chirp的一些
设定 还有像advanced[听不清]的设定
advanced[听不清]的一些设定
那这个都还蛮关键的
都还蛮关键的
好 那我们就先讲到这里
3.0 3.0还蛮行的 3.0是跟着mmwave SDK3.0 它是跟着iwr6843 在一起出来的 也就是在这个月的月初 我们现在看它到底有什么新的东西 新的东西比较有意义的 我把它用红色的线标出来了 我个人觉得比较有意义的 比如说这边,当然它这个3.0出来 为的就是要support iwr6843 它内部其实也带了1843的drivers 所以SDK3.0理论上已经可以驱动1843的板子 没有问题 然后driver有做一些update 不过这应该minor的 然后mmwaveLib它有增加一些新的东西 然后group tracker,过去的group tracker是2D 现在有3D 3D的点源 当然,最有意义的就是这种 所谓的scalable architecture 这种scalable architecture呢 它就是,它最主要要解决的问题就是 刚才讲的,在这么多应题的competition之下 在这么多应用的competition之下 我要如何做出一个有弹性的software 反馈 这个它有像DPU DPC DPIF DPM DPEDMA 那DP都是data processing的意思 那DPU就是data processing unit DPC就是data processing chain 然后有DPIF interface 还有manager 等一下我们就会慢慢看到 然后还有一些demo的改动了 另外一个很重要的 secondary的bootloader 如果你要量产产品的话 secondary bootloader一定不可少 因为你终究要做产品 要做[听不清]的update 那这个一定是要在secondary bootloader 那为什么把它叫secondary bootloader 因为我们第一个BootLoader就是bootl bootl已经消失在IC里面 已经没办法改了 bootl所有的[听不清]和IC 开始都是bootl先执行 执行完之后 控制权就会交到使用者的application 那使用者的第一次application是 在传统上应该就是 我们把它叫做secondary bootloader secondary bootloader要做什么事 就是 更新分类 还有做一大堆你想要的事 比如说你搞不好想要在里面做一些产测 你要做一些产测的流程 你要做一些其他的东西 反正你爱怎么写就怎么写 secondary bootloader 我们TI其实也蛮贴心的 据我所知 没有一家其他的 像其他secondary BootLoader大概都要自己写 其实这个一般来说都要自己写 不应该是[听不清]来帮你写 为什么呢 因为secondary bootloader就是代表你的一些产线 产测等等流程 你要怎么update你的分类等等的 这种事实上都是非常customize的东西 非常customize的software 但是我们有写一个sample 所以你看这个 应该就可以写出自己的secondary BootLoader 这样会加速你的开发进度 好 那3.0的architecture呢 回到刚刚的主题 3.0的architecture到底跟过去的二点多有什么不同 首先 过去的SDK 一点多 二点多 它的处理链事实上是跟你的mmWave demo是捆在一起的 换句话说 你的application跟你的chain是混在一起的 那这样有什么缺点 有什么缺点 等于说你今天就没有办法 一直reuse这字的东西 没有办法一直reuse这样子的东西 所以我们现在要做的呢 首先呢 我们要把chain 从application把它分离出来 把它抽出来 让它更独立 更独立有很多好处 就代表说 你以后工业可能有成千上百的应用 比如说像现在就有people counting 有做空间占据的一些等等的 可能未来还有更多的应用 每个应用的chain可能就长得不一样 所以说你以后只要抽换掉这些chain就可以了 就不像过去 因为两个已经搅和在一起 就很难 你就等于全部UR这边就要重写就是了 我们的想法就是说 以后你可以抽换这个chain 可以抽换这个chain 这个chain就是 DPC 我们刚刚提到的 data processing chain DPC呢 我们可以把它想象成一条工厂的生产线 每条生产线上面就有很多机台 对不对 每一个机台就是一个DPU 好不好 所以这样是不是很简单 所以一个chain里面就有很多DPU 每个DPU就去做它的事情 每个DPU就去做它的事情 比如说 你今天要做range的FFT 就会有个range的FFT的DPU 你今天要做CFAR的 CFAR的那个...... 部分 就会有一个CFAR的DPU 类似这样子 好 好 所以这个是第一个 你可以看到这样的改变 好 那接着呢 橘色这边框出来的都是有改变的部分 有改变的部分 更细节的改变是包含了 比如说 因为在雷达这边 我们理解到就是说 有些客户对[听不清] 尤其是一些工业的那个 客户对[听不清]事实上不熟悉的 那你必须要引进一些third party 对吧 那可是如果像过去的那种 那种application跟整个处理链全部混在一起的话 其实对third party而言 [听不清]的third party或provider而言 他们会变得很麻烦 没有办法跟你的application切割开来 所以我们希望的是 像一些third party 它能够直接提供产线的机台 make sense吗 好 就是说 你可以 你可以 比如说你今天 一个[听不清]的third party就 create自己的DPU 然后这个DPU就可以被plug in到整个chain里面的一部分 所以这样的话也可能达成就是说 对这种third party而言 他们以后就好办事 好办事 对 DPIF 这个东西很妙 如果你去trace call的话 没有[听不清] 它就是纯粹的一些 资料结构的DH档 讲白了 这个部分呢 都是在讲一些 DPIF都是在讲一些 在整个链里面 一定都会伴随着 资料 这些资料包含了像 ADC buffer 像这边提到的 或者雷达cube 或者detection metrics 等等的 这个就是data path interface DPIF 然后 data path manager DPM DPM事实上就是来管理 管理DPC的 所以如果你去看DPM的 在做一些 initialization的时候就会发觉 DPM initialize的时候 它就会去指定说你今天要去挂哪一条 把哪一条链给挂上去 就呼应了我刚才的讲法 你今天不同应用可能就要挂上不一样的链 所以它的设计哲学就变得不太一样 每条链的DPU都是可以独立的 好 这个就是刚刚讲的 scalable chain concept 就是我刚才讲的 因为你会有不同的HWA 你可能要走HWA或者是DSP 所以你必须要这种 它就是 像这个 就是range的DPU range的FFTE以后可能在HWA service做 也有可能在DSP做 所以你的DPU你就会准备 准备两种 对 DPU就会准备两种 那这个雷达cube的 这些format 像这个 你要 知道它的格式的长相就是 从 DPIF就可以去看到雷达cube的长相 大体上是这样子 我觉得这个设计的方向是非常正确的 只不过 如果从软体的角度来看 其实这个是比较不容易了解 因为过去就是 一条线通到底 刚才我看mmWave demo application 我就一路看到底 它整个流程大概就知道了 但是它现在把它抽象化以后 就是 就变成一个模组这样子 从软体工程的角度来看是对的 但是 读上面会比较复杂一点 好 那这也是刚才有提过的 DPM DPM可以挂不同的DPC DPC是由各式各样的DPU组成 所以以后各位的程式里面 可能可以准备 很多条DPC 每条DPC都可以准备不同的DPU DPU当然就是有些可以共用 有些不能共用 来保持它的弹性 大体上就是这样子的部分 那DPEDMA 这个就没什么 我想大概也不会有人要去改它 反正DEMA都是搬资料 这种东西大概不会有人要去改它 好 会去动的 我觉得就是 DPU 就说 嗯 因为你们都会有自己的 想要做的 algorithm 所以你也可以create自己的DPU 然后插到整个链里面去 好 那这个是我刚才讲的 你看这张图要表达就是 它想把application开发者跟algorithm processing chain的开发者要去把它分开来 去把它分开来 要去做这样的事情 OK 这是DPIF DPIF就是ADC的雷达cube 这些电云 好 然后DPU它的function code大概都是这种样子 init config process control还有deinit 那当然了 主要的流程一定都是写在 process 这边 做process之前 要先config 对 好 然后 因为 我这边还有用红色的框起来 所有的memory location for io buffer 好 是在DPU 外面去allocate DPU本身 DPU本身并不去挖memory 为什么会这样子 是因为 其实 其实memory有限 再加上 整条链的流程里面 其实有很多的 资料是要共享的 如果每个DPU都去挖自己的 就会有点你也挖我也挖 就资源浪费 因为它 像雷达cube 它可能有两个DPU都要同时access雷达cube 对吧 好 是这样子的原因 好 这个是data processing chain callback function等等 OK 那它的 目录的架构 你看 也跟过去长得不太一样 过去我想 control这边 control这边还是有啦 好像就是mmWave DPM这边 然后 datapath 目前主要的呢 以后要看的可能最主要的就要落在 TI下面datapath这个目录下面 这个demo是属于application mmWave Demo这种东西 因为它的处理链已经被抽出来了 所以 这个理论上来讲 size会变小 然后这边 被抽出来的部分都会被放到 比如说像 DPC DPC里面 或者是DPU下面 这边 比如说这边就有一个range的 DPU 然后这个DPC下面又 挂各式各样的 像dopplerproc 或者是AOA的 DPU的 就挂住这边 然后 这个是objectdetection 目前我们挂上去的DPC就是objectdetection 如果以后你要做自己的链的话 很明显的你就是在这边再create一个folder 叫自己的一个名字 然后 就去调用这些DPU 各式各样的DPU 来使用 所以我觉得这个逻辑上就 蛮make sense的 这样也可以解决到时候 我们刚才提到的那些问题 还蛮不错的 只不过对过去熟悉1.0和2.0的人 就比较辛苦一点 要重新 重新思考这样子的架构 好 DPU DPU 像刚刚的cluster removal 把静止的移除的那种 DPU就放在这边 每个DPU到时候都会有source code 还有document 那document当然还是用doc doc那种东西所存在的 好 我想call flow我们就不用再一个一个过了 这种call flow在mmWave SDK3.0的概念里面 其实就有画出来 大家就去看一看 基本上就是 是怎么样 调用它 DPM怎么样调用DPC DPC怎么样调用DPU 大概就是这样子 所以我是觉得还好 还好 好 那这个 我想我们 时间也好像也有点超过了 我是不知道能超过多久 但是 像这些东西 其实要讲可以讲很久 我们今天时间不是那么充足 像这个各式各样的DPU的介绍 介绍 好 好 那 我觉得就是只要掌握基本原理的话 就比较容易看得懂 看得懂它背后的思维到底是什么 那这个每个DPU我就不去过它 那我最后再讲一个 这个3.0 我最后再讲一个 memory 这个是based on mmWave SDK 1.多2.多 那样子的长相 我自己 因为挖memory一向都是很重要的 课题 尤其是我们的memory 都是设计得蛮刚好 我觉得哈 真的还蛮厉害的 每次都设计得刚刚好 在margin边缘 好 这个是1642的 1642的memory的部分 你可以看到有这么多块吗 那我把 这边全部加在一起 就是刚才讲到的1.5Megabit 那雷达的cube都是放在这边 雷达的cube放在这边 影响到我们的 像过去 如果你是挖memory的话 挖memory的话 过去mmWave SKD 还蛮简单的 各位有注意到这边吗 这边有一个function code 在mmWave SDK 里面 这个function code datapath的config buffer 这个function code里面 事实上就是去负责去 你就会看到里面有呼叫很多 memory location的function 那那些memory location的function 就去负责挖这些所有记忆体的配置 那我们先从L3这边看起 L3这边有几个buffer是放在L3这边 最重要的当然就是雷达cube了 然后还有一些ADC的data buffer等等 那这边我写好一些试算表 就是说你只要输入你今天range FFT是多少 doppler FFT是多少 有多少T多少R对不对 你就可以 计算出 memory cube的size要多大 像因为我们刚刚看到 L3的memory 大概只有768k 所以我们的目前的配置 比如说以164 它是一个 二梯式这样的一个 架构之下 我们的配置大概就是25664 mmWave demo 它用的 配置也是25664这样子的配置 我们比较特别的 就是里面每一个element 都是complex 刚刚不是有提到 real的base band跟complex的base band吗 好 因为我们是使用complex的base band 所以它每个资料形态全部都是complex 每个complex都是带有实数部跟虚数部 然后都是4个bit 都是4个bit 所以呢 这边 是它的公式 就是说雷达cube是用什么样的方式 在做memory location的 好 我做这个表 反正我就是直接看source code 它memory location怎么样挖 它是base on什么样条件去挖 我就把它条件写在这边 所以就可以算得出来 然后这个可以搭配这个一起看 我想这个流程图 这个流程图是 mmWave demo的流程图 我这边就把一些注解上去 我把它注解上去 它是怎么样去挖的 那这个要花一点时间去理解 因为这个东西不是这么好理解 然后我们 那个demo的[听不清]的打法是这种样子 如果你是1642mmWave demo的话 那它的 它是 Tx1 先打一个chirp 1 接着换一个Tx2 打一个chirp 2 这样子 它的设定 原来设定是这样子 好 这个chirp1 chirp2 到时候 Rx回来的时候 它就是 这一列就是Tx1 的资料 然后这个是Tx2的资料 等等 好 这样子 那当然这个都是 其实这个都 是资料搬来搬去 交错来交错去 这种要花一点时间理解 其实这个图还蛮重要的 好 那我想 我们在mmWave SDK 这边大概就先暂时讲到这边 那还有一些东西的话 可能在下午的 如果有时间的话我们再继续讲 因为我还想讲的包含了 比如说chirp chirp的一些 设定 还有像advanced[听不清]的设定 advanced[听不清]的一些设定 那这个都还蛮关键的 都还蛮关键的 好 那我们就先讲到这里
3.0 3.0还蛮行的
3.0是跟着mmwave SDK3.0
它是跟着iwr6843
在一起出来的
也就是在这个月的月初
我们现在看它到底有什么新的东西
新的东西比较有意义的
我把它用红色的线标出来了
我个人觉得比较有意义的
比如说这边,当然它这个3.0出来
为的就是要support iwr6843
它内部其实也带了1843的drivers
所以SDK3.0理论上已经可以驱动1843的板子
没有问题
然后driver有做一些update
不过这应该minor的
然后mmwaveLib它有增加一些新的东西
然后group tracker,过去的group tracker是2D
现在有3D
3D的点源
当然,最有意义的就是这种
所谓的scalable architecture
这种scalable architecture呢
它就是,它最主要要解决的问题就是
刚才讲的,在这么多应题的competition之下
在这么多应用的competition之下
我要如何做出一个有弹性的software 反馈
这个它有像DPU DPC DPIF DPM
DPEDMA
那DP都是data processing的意思
那DPU就是data processing unit
DPC就是data processing chain
然后有DPIF interface 还有manager
等一下我们就会慢慢看到
然后还有一些demo的改动了 另外一个很重要的
secondary的bootloader
如果你要量产产品的话
secondary bootloader一定不可少
因为你终究要做产品 要做[听不清]的update
那这个一定是要在secondary bootloader
那为什么把它叫secondary bootloader
因为我们第一个BootLoader就是bootl
bootl已经消失在IC里面
已经没办法改了
bootl所有的[听不清]和IC
开始都是bootl先执行
执行完之后 控制权就会交到使用者的application
那使用者的第一次application是
在传统上应该就是
我们把它叫做secondary bootloader
secondary bootloader要做什么事 就是
更新分类 还有做一大堆你想要的事
比如说你搞不好想要在里面做一些产测
你要做一些产测的流程 你要做一些其他的东西
反正你爱怎么写就怎么写
secondary bootloader
我们TI其实也蛮贴心的
据我所知 没有一家其他的
像其他secondary BootLoader大概都要自己写
其实这个一般来说都要自己写
不应该是[听不清]来帮你写 为什么呢
因为secondary bootloader就是代表你的一些产线 产测等等流程
你要怎么update你的分类等等的
这种事实上都是非常customize的东西
非常customize的software
但是我们有写一个sample
所以你看这个 应该就可以写出自己的secondary BootLoader
这样会加速你的开发进度
好 那3.0的architecture呢 回到刚刚的主题
3.0的architecture到底跟过去的二点多有什么不同
首先 过去的SDK 一点多 二点多
它的处理链事实上是跟你的mmWave demo是捆在一起的
换句话说 你的application跟你的chain是混在一起的
那这样有什么缺点
有什么缺点 等于说你今天就没有办法
一直reuse这字的东西
没有办法一直reuse这样子的东西
所以我们现在要做的呢 首先呢 我们要把chain
从application把它分离出来
把它抽出来
让它更独立
更独立有很多好处
就代表说 你以后工业可能有成千上百的应用
比如说像现在就有people counting
有做空间占据的一些等等的
可能未来还有更多的应用
每个应用的chain可能就长得不一样
所以说你以后只要抽换掉这些chain就可以了
就不像过去 因为两个已经搅和在一起
就很难 你就等于全部UR这边就要重写就是了
我们的想法就是说
以后你可以抽换这个chain
可以抽换这个chain 这个chain就是
DPC 我们刚刚提到的 data processing chain
DPC呢 我们可以把它想象成一条工厂的生产线
每条生产线上面就有很多机台 对不对
每一个机台就是一个DPU
好不好 所以这样是不是很简单
所以一个chain里面就有很多DPU
每个DPU就去做它的事情
每个DPU就去做它的事情
比如说 你今天要做range的FFT
就会有个range的FFT的DPU
你今天要做CFAR的 CFAR的那个......
部分 就会有一个CFAR的DPU
类似这样子
好 好 所以这个是第一个 你可以看到这样的改变
好 那接着呢
橘色这边框出来的都是有改变的部分
有改变的部分 更细节的改变是包含了 比如说
因为在雷达这边 我们理解到就是说
有些客户对[听不清] 尤其是一些工业的那个
客户对[听不清]事实上不熟悉的
那你必须要引进一些third party
对吧 那可是如果像过去的那种
那种application跟整个处理链全部混在一起的话
其实对third party而言 [听不清]的third party或provider而言
他们会变得很麻烦 没有办法跟你的application切割开来
所以我们希望的是 像一些third party
它能够直接提供产线的机台
make sense吗 好 就是说 你可以
你可以 比如说你今天 一个[听不清]的third party就
create自己的DPU
然后这个DPU就可以被plug in到整个chain里面的一部分
所以这样的话也可能达成就是说
对这种third party而言 他们以后就好办事
好办事 对
DPIF 这个东西很妙
如果你去trace call的话
没有[听不清] 它就是纯粹的一些
资料结构的DH档
讲白了 这个部分呢
都是在讲一些 DPIF都是在讲一些
在整个链里面 一定都会伴随着
资料 这些资料包含了像
ADC buffer 像这边提到的
或者雷达cube
或者detection metrics
等等的 这个就是data path interface DPIF
然后 data path manager
DPM DPM事实上就是来管理
管理DPC的 所以如果你去看DPM的 在做一些
initialization的时候就会发觉 DPM initialize的时候
它就会去指定说你今天要去挂哪一条
把哪一条链给挂上去
就呼应了我刚才的讲法
你今天不同应用可能就要挂上不一样的链
所以它的设计哲学就变得不太一样
每条链的DPU都是可以独立的
好 这个就是刚刚讲的
scalable chain concept 就是我刚才讲的
因为你会有不同的HWA
你可能要走HWA或者是DSP
所以你必须要这种 它就是
像这个 就是range的DPU
range的FFTE以后可能在HWA service做
也有可能在DSP做
所以你的DPU你就会准备
准备两种
对 DPU就会准备两种
那这个雷达cube的
这些format 像这个 你要
知道它的格式的长相就是
从 DPIF就可以去看到雷达cube的长相
大体上是这样子
我觉得这个设计的方向是非常正确的
只不过 如果从软体的角度来看
其实这个是比较不容易了解 因为过去就是
一条线通到底 刚才我看mmWave demo
application 我就一路看到底
它整个流程大概就知道了
但是它现在把它抽象化以后 就是
就变成一个模组这样子
从软体工程的角度来看是对的
但是 读上面会比较复杂一点 好
那这也是刚才有提过的 DPM
DPM可以挂不同的DPC
DPC是由各式各样的DPU组成
所以以后各位的程式里面 可能可以准备
很多条DPC 每条DPC都可以准备不同的DPU
DPU当然就是有些可以共用 有些不能共用
来保持它的弹性
大体上就是这样子的部分
那DPEDMA 这个就没什么 我想大概也不会有人要去改它
反正DEMA都是搬资料
这种东西大概不会有人要去改它
好 会去动的 我觉得就是
DPU 就说 嗯
因为你们都会有自己的 想要做的
algorithm 所以你也可以create自己的DPU
然后插到整个链里面去
好 那这个是我刚才讲的
你看这张图要表达就是
它想把application开发者跟algorithm
processing chain的开发者要去把它分开来
去把它分开来
要去做这样的事情
OK
这是DPIF
DPIF就是ADC的雷达cube 这些电云
好
然后DPU它的function code大概都是这种样子
init config process control还有deinit
那当然了 主要的流程一定都是写在
process 这边
做process之前 要先config
对 好
然后 因为 我这边还有用红色的框起来
所有的memory location for io buffer
好 是在DPU
外面去allocate
DPU本身
DPU本身并不去挖memory 为什么会这样子 是因为
其实
其实memory有限 再加上
整条链的流程里面 其实有很多的
资料是要共享的 如果每个DPU都去挖自己的
就会有点你也挖我也挖 就资源浪费
因为它 像雷达cube
它可能有两个DPU都要同时access雷达cube
对吧 好 是这样子的原因
好 这个是data processing chain
callback function等等
OK 那它的
目录的架构 你看
也跟过去长得不太一样
过去我想 control这边
control这边还是有啦 好像就是mmWave
DPM这边 然后
datapath 目前主要的呢
以后要看的可能最主要的就要落在
TI下面datapath这个目录下面
这个demo是属于application
mmWave Demo这种东西
因为它的处理链已经被抽出来了 所以
这个理论上来讲 size会变小
然后这边 被抽出来的部分都会被放到
比如说像 DPC
DPC里面
或者是DPU下面
这边 比如说这边就有一个range的
DPU 然后这个DPC下面又
挂各式各样的 像dopplerproc
或者是AOA的 DPU的 就挂住这边
然后 这个是objectdetection
目前我们挂上去的DPC就是objectdetection
如果以后你要做自己的链的话
很明显的你就是在这边再create一个folder
叫自己的一个名字
然后 就去调用这些DPU 各式各样的DPU
来使用 所以我觉得这个逻辑上就
蛮make sense的
这样也可以解决到时候 我们刚才提到的那些问题
还蛮不错的
只不过对过去熟悉1.0和2.0的人
就比较辛苦一点 要重新
重新思考这样子的架构
好 DPU DPU
像刚刚的cluster removal
把静止的移除的那种
DPU就放在这边
每个DPU到时候都会有source code
还有document 那document当然还是用doc
doc那种东西所存在的
好 我想call flow我们就不用再一个一个过了
这种call flow在mmWave SDK3.0的概念里面
其实就有画出来
大家就去看一看 基本上就是
是怎么样 调用它 DPM怎么样调用DPC
DPC怎么样调用DPU
大概就是这样子 所以我是觉得还好
还好 好 那这个 我想我们
时间也好像也有点超过了
我是不知道能超过多久 但是
像这些东西
其实要讲可以讲很久 我们今天时间不是那么充足
像这个各式各样的DPU的介绍
介绍 好
好 那 我觉得就是只要掌握基本原理的话
就比较容易看得懂
看得懂它背后的思维到底是什么
那这个每个DPU我就不去过它
那我最后再讲一个
这个3.0 我最后再讲一个
memory
这个是based on mmWave SDK 1.多2.多
那样子的长相
我自己 因为挖memory一向都是很重要的
课题 尤其是我们的memory
都是设计得蛮刚好 我觉得哈
真的还蛮厉害的
每次都设计得刚刚好 在margin边缘
好
这个是1642的
1642的memory的部分
你可以看到有这么多块吗
那我把 这边全部加在一起
就是刚才讲到的1.5Megabit
那雷达的cube都是放在这边
雷达的cube放在这边
影响到我们的 像过去
如果你是挖memory的话
挖memory的话
过去mmWave SKD
还蛮简单的 各位有注意到这边吗
这边有一个function code
在mmWave SDK
里面 这个function code datapath的config buffer
这个function code里面
事实上就是去负责去 你就会看到里面有呼叫很多
memory location的function
那那些memory location的function
就去负责挖这些所有记忆体的配置
那我们先从L3这边看起
L3这边有几个buffer是放在L3这边
最重要的当然就是雷达cube了
然后还有一些ADC的data buffer等等
那这边我写好一些试算表
就是说你只要输入你今天range FFT是多少
doppler FFT是多少
有多少T多少R对不对 你就可以
计算出 memory cube的size要多大
像因为我们刚刚看到 L3的memory
大概只有768k
所以我们的目前的配置
比如说以164 它是一个
二梯式这样的一个
架构之下 我们的配置大概就是25664
mmWave demo 它用的
配置也是25664这样子的配置
我们比较特别的 就是里面每一个element
都是complex 刚刚不是有提到
real的base band跟complex的base band吗
好 因为我们是使用complex的base band
所以它每个资料形态全部都是complex
每个complex都是带有实数部跟虚数部
然后都是4个bit
都是4个bit 所以呢 这边
是它的公式
就是说雷达cube是用什么样的方式
在做memory location的
好 我做这个表 反正我就是直接看source code
它memory location怎么样挖
它是base on什么样条件去挖 我就把它条件写在这边
所以就可以算得出来
然后这个可以搭配这个一起看
我想这个流程图 这个流程图是
mmWave demo的流程图
我这边就把一些注解上去
我把它注解上去
它是怎么样去挖的
那这个要花一点时间去理解
因为这个东西不是这么好理解 然后我们
那个demo的[听不清]的打法是这种样子
如果你是1642mmWave demo的话
那它的 它是
Tx1 先打一个chirp 1 接着换一个Tx2
打一个chirp 2 这样子
它的设定 原来设定是这样子
好 这个chirp1 chirp2 到时候
Rx回来的时候
它就是 这一列就是Tx1
的资料
然后这个是Tx2的资料 等等
好 这样子
那当然这个都是 其实这个都
是资料搬来搬去
交错来交错去
这种要花一点时间理解
其实这个图还蛮重要的
好 那我想
我们在mmWave SDK
这边大概就先暂时讲到这边
那还有一些东西的话 可能在下午的
如果有时间的话我们再继续讲
因为我还想讲的包含了
比如说chirp chirp的一些
设定 还有像advanced[听不清]的设定
advanced[听不清]的一些设定
那这个都还蛮关键的
都还蛮关键的
好 那我们就先讲到这里
手机看
扫码用手机观看
 视频简介
视频简介
mmWave SDK简介
所属课程:汽车/工业 毫米波雷达感测器
发布时间:2018.12.03
视频集数:6
本节视频时长:00:22:45
本课程介绍了TI mmWave解决方案;60GHz mmWave传感器;60GHz vs. 24GHz;mm波伏电源解决方案和BOM估算;mmWave SDK 。


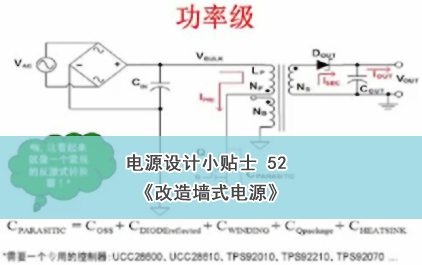



 未学习 TI mmWave解决方案
未学习 TI mmWave解决方案
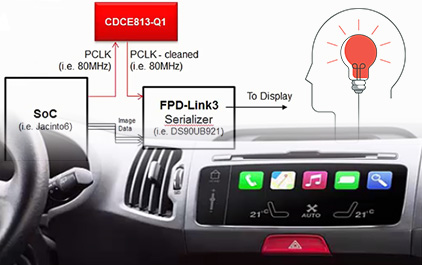
 未学习 60GHz mmWave传感器
未学习 60GHz mmWave传感器
 未学习 60GHz vs. 24GHz
未学习 60GHz vs. 24GHz
 未学习 mm波伏电源解决方案和BOM估算
未学习 mm波伏电源解决方案和BOM估算
 未学习 mmWave SDK
未学习 mmWave SDK
 未学习 mmWave SDK简介
未学习 mmWave SDK简介






