低能耗加速器(LEA)性能
Loading the player...
将在30s后自动为您播放下一课程
在接下来的 几张幻灯片中, 我将通过考察 LEA 周期 和能效来谈谈 LEA 的性能。 正如前面所述, LEA 是一款用于执行信号处理的 高效加速器。 让我们更仔细地 考察 LEA 的性能,例如, 使用 LEA 而非 CMSIS-DSP 库的 16 位复数 256 点 FFT, 大约比 CM-0+ 快 39 倍, 比 C-M3 快 8 倍, 而且比此处的 C-M4F 快 3 倍。 此外,还注意到 许多执行 512 点 FFT 的 周期都相当线性。 仅就执行 FFT 而言, 这也是显著的性能提升, 尤其是相对于 C-M0+ 内核。 如果您看一看 使用 加速器 LEA 执行 256 点复数 FFT 相对于未加速情况下的耗能影响, 您会发现,在未加速情况下, 只有一个传统 CPU 用于计算 FFT, 而这不包括 应用程序的其他部分; 看一看执行类似操作 所需的 纯 CPU 周期, 您会发现,LEA 可以 显著改善执行时间。 使用 LEA 的 平均 [听不清] 要慢于 CPU。 而最终这就表现为采用 LPM0 执行 FFT 的总耗能 约有 27 倍的 耗能改善。 如果看一看 LEA, 其耗能已在右侧列出, 它的耗能改善 约有 20 倍。 这表示正在 由 LEA 执行 特定任务且由 CPU 以并行方式执行 单独任务的 应用程序。 现在, 当然, 了解 LEA 对整个应用程序的 总体影响也非常重要。 这当然会因您的应用程序 不同而存在差异。 在我们的示例中,我们以每秒 从麦克风输出中采集 8kHz 样本的 采样率从 ADC 获得 256 个样本。 我们可以在使用 LEA 和 不使用 LEA 的两种情况下 执行复数 256 点 FFT。 然后,我们 将测量 使用 LEA 加速的 FFT 与未加速 FFT 的 系统耗能。 请注意, 此耗能包括 ADC、麦克风、 模拟前端,并且 显示器处于活跃状态。 看看接下来 两张幻灯片上给出的结果。 您将看到在使用 LEA 的条件下 执行 FFT 相比不使用 LEA 的情况, 能效提升约 20 倍 且速度提升 约 14.5 倍。 您在此可以看到, MSP430 以 8 兆赫运行, 只需约 2,680 微秒 即可执行 256 点 复数 FFT。 如果不使用 LEA,执行此操作 在兆赫频率下约需 9.7 毫秒。 您还将在此 观察到平均电流 包括组合在一起的 信号处理 BoosterPack 以及 Sharp LCD BoosterPack。 不过,再来看看 LEA 如何影响整个 应用程序也许更有用处。 此例情况相同。 我们对 ADC 采样, 执行 FFT, 然后刷新显示屏。 现在,LEA 产生的总体影响 是将能效提高约 1.4 倍。 它还将应用 时间缩短 21%,这意味着主 CPU 现在能够完成更多任务。 让我们来看看 LEA 与 MSP432 仅在执行 FFT 方面的 性能对比情况。 MSP432 基于 Cortex-M4F, 只需 1.5 毫秒即可 执行 256 点复数 FFT。 在耗能比较方面,仅 LEA 的 能效就比 MSP432 大约高 3.3 倍。 在此情况下,LEA 可通过两种方式 帮助您的应用程序。 虽然使用 16 位 MCU 仍能够处理您的 主应用程序,但却在处理、信号 处理以及实时处理方面 面临着计算限制。 而使用 LEA 可以 为您的主应用程序 减轻信号处理负载, 使主 CPU 能够 并行执行任务, 从而提高 应用程序吞吐量。 除并行计算外, 另一方面, LEA 还能够帮助 降低您的 系统耗能, 您可以将信号处理 功能卸载至 加速器。 如先前 幻灯片中所见, 显然,LEA 能够 降低系统耗能, 同时还能够以显著加快的 速度执行信号处理任务
在接下来的 几张幻灯片中, 我将通过考察 LEA 周期 和能效来谈谈 LEA 的性能。 正如前面所述, LEA 是一款用于执行信号处理的 高效加速器。 让我们更仔细地 考察 LEA 的性能,例如, 使用 LEA 而非 CMSIS-DSP 库的 16 位复数 256 点 FFT, 大约比 CM-0+ 快 39 倍, 比 C-M3 快 8 倍, 而且比此处的 C-M4F 快 3 倍。 此外,还注意到 许多执行 512 点 FFT 的 周期都相当线性。 仅就执行 FFT 而言, 这也是显著的性能提升, 尤其是相对于 C-M0+ 内核。 如果您看一看 使用 加速器 LEA 执行 256 点复数 FFT 相对于未加速情况下的耗能影响, 您会发现,在未加速情况下, 只有一个传统 CPU 用于计算 FFT, 而这不包括 应用程序的其他部分; 看一看执行类似操作 所需的 纯 CPU 周期, 您会发现,LEA 可以 显著改善执行时间。 使用 LEA 的 平均 [听不清] 要慢于 CPU。 而最终这就表现为采用 LPM0 执行 FFT 的总耗能 约有 27 倍的 耗能改善。 如果看一看 LEA, 其耗能已在右侧列出, 它的耗能改善 约有 20 倍。 这表示正在 由 LEA 执行 特定任务且由 CPU 以并行方式执行 单独任务的 应用程序。 现在, 当然, 了解 LEA 对整个应用程序的 总体影响也非常重要。 这当然会因您的应用程序 不同而存在差异。 在我们的示例中,我们以每秒 从麦克风输出中采集 8kHz 样本的 采样率从 ADC 获得 256 个样本。 我们可以在使用 LEA 和 不使用 LEA 的两种情况下 执行复数 256 点 FFT。 然后,我们 将测量 使用 LEA 加速的 FFT 与未加速 FFT 的 系统耗能。 请注意, 此耗能包括 ADC、麦克风、 模拟前端,并且 显示器处于活跃状态。 看看接下来 两张幻灯片上给出的结果。 您将看到在使用 LEA 的条件下 执行 FFT 相比不使用 LEA 的情况, 能效提升约 20 倍 且速度提升 约 14.5 倍。 您在此可以看到, MSP430 以 8 兆赫运行, 只需约 2,680 微秒 即可执行 256 点 复数 FFT。 如果不使用 LEA,执行此操作 在兆赫频率下约需 9.7 毫秒。 您还将在此 观察到平均电流 包括组合在一起的 信号处理 BoosterPack 以及 Sharp LCD BoosterPack。 不过,再来看看 LEA 如何影响整个 应用程序也许更有用处。 此例情况相同。 我们对 ADC 采样, 执行 FFT, 然后刷新显示屏。 现在,LEA 产生的总体影响 是将能效提高约 1.4 倍。 它还将应用 时间缩短 21%,这意味着主 CPU 现在能够完成更多任务。 让我们来看看 LEA 与 MSP432 仅在执行 FFT 方面的 性能对比情况。 MSP432 基于 Cortex-M4F, 只需 1.5 毫秒即可 执行 256 点复数 FFT。 在耗能比较方面,仅 LEA 的 能效就比 MSP432 大约高 3.3 倍。 在此情况下,LEA 可通过两种方式 帮助您的应用程序。 虽然使用 16 位 MCU 仍能够处理您的 主应用程序,但却在处理、信号 处理以及实时处理方面 面临着计算限制。 而使用 LEA 可以 为您的主应用程序 减轻信号处理负载, 使主 CPU 能够 并行执行任务, 从而提高 应用程序吞吐量。 除并行计算外, 另一方面, LEA 还能够帮助 降低您的 系统耗能, 您可以将信号处理 功能卸载至 加速器。 如先前 幻灯片中所见, 显然,LEA 能够 降低系统耗能, 同时还能够以显著加快的 速度执行信号处理任务
在接下来的 几张幻灯片中,
我将通过考察 LEA 周期 和能效来谈谈 LEA 的性能。
正如前面所述, LEA 是一款用于执行信号处理的
高效加速器。
让我们更仔细地 考察 LEA 的性能,例如,
使用 LEA 而非 CMSIS-DSP 库的 16 位复数 256 点 FFT,
大约比 CM-0+ 快 39 倍,
比 C-M3 快 8 倍, 而且比此处的 C-M4F 快 3 倍。
此外,还注意到 许多执行
512 点 FFT 的 周期都相当线性。
仅就执行 FFT 而言, 这也是显著的性能提升,
尤其是相对于 C-M0+ 内核。
如果您看一看 使用
加速器 LEA 执行 256 点复数 FFT 相对于未加速情况下的耗能影响,
您会发现,在未加速情况下, 只有一个传统 CPU
用于计算 FFT, 而这不包括
应用程序的其他部分; 看一看执行类似操作
所需的 纯 CPU 周期,
您会发现,LEA 可以 显著改善执行时间。
使用 LEA 的 平均 [听不清] 要慢于 CPU。
而最终这就表现为采用 LPM0 执行 FFT 的总耗能
约有 27 倍的 耗能改善。
如果看一看 LEA, 其耗能已在右侧列出,
它的耗能改善 约有 20 倍。
这表示正在 由 LEA 执行
特定任务且由 CPU 以并行方式执行
单独任务的 应用程序。
现在, 当然,
了解 LEA 对整个应用程序的 总体影响也非常重要。
这当然会因您的应用程序 不同而存在差异。
在我们的示例中,我们以每秒 从麦克风输出中采集 8kHz 样本的
采样率从 ADC 获得 256 个样本。
我们可以在使用 LEA 和 不使用 LEA 的两种情况下
执行复数 256 点 FFT。
然后,我们 将测量
使用 LEA 加速的 FFT 与未加速 FFT 的
系统耗能。
请注意, 此耗能包括
ADC、麦克风、 模拟前端,并且
显示器处于活跃状态。
看看接下来 两张幻灯片上给出的结果。
您将看到在使用 LEA 的条件下 执行 FFT 相比不使用 LEA 的情况,
能效提升约 20 倍 且速度提升
约 14.5 倍。
您在此可以看到, MSP430 以 8 兆赫运行,
只需约 2,680 微秒 即可执行 256 点
复数 FFT。
如果不使用 LEA,执行此操作 在兆赫频率下约需 9.7
毫秒。
您还将在此 观察到平均电流
包括组合在一起的 信号处理 BoosterPack
以及 Sharp LCD BoosterPack。
不过,再来看看 LEA 如何影响整个
应用程序也许更有用处。
此例情况相同。
我们对 ADC 采样, 执行 FFT,
然后刷新显示屏。
现在,LEA 产生的总体影响 是将能效提高约 1.4
倍。
它还将应用 时间缩短
21%,这意味着主 CPU 现在能够完成更多任务。
让我们来看看 LEA 与 MSP432 仅在执行 FFT 方面的
性能对比情况。
MSP432 基于 Cortex-M4F,
只需 1.5 毫秒即可 执行 256 点复数 FFT。
在耗能比较方面,仅 LEA 的 能效就比 MSP432
大约高 3.3 倍。
在此情况下,LEA 可通过两种方式 帮助您的应用程序。
虽然使用 16 位 MCU 仍能够处理您的
主应用程序,但却在处理、信号 处理以及实时处理方面
面临着计算限制。
而使用 LEA 可以 为您的主应用程序
减轻信号处理负载, 使主 CPU 能够
并行执行任务,
从而提高 应用程序吞吐量。
除并行计算外,
另一方面, LEA 还能够帮助
降低您的 系统耗能,
您可以将信号处理 功能卸载至
加速器。
如先前 幻灯片中所见,
显然,LEA 能够 降低系统耗能,
同时还能够以显著加快的 速度执行信号处理任务
在接下来的 几张幻灯片中, 我将通过考察 LEA 周期 和能效来谈谈 LEA 的性能。 正如前面所述, LEA 是一款用于执行信号处理的 高效加速器。 让我们更仔细地 考察 LEA 的性能,例如, 使用 LEA 而非 CMSIS-DSP 库的 16 位复数 256 点 FFT, 大约比 CM-0+ 快 39 倍, 比 C-M3 快 8 倍, 而且比此处的 C-M4F 快 3 倍。 此外,还注意到 许多执行 512 点 FFT 的 周期都相当线性。 仅就执行 FFT 而言, 这也是显著的性能提升, 尤其是相对于 C-M0+ 内核。 如果您看一看 使用 加速器 LEA 执行 256 点复数 FFT 相对于未加速情况下的耗能影响, 您会发现,在未加速情况下, 只有一个传统 CPU 用于计算 FFT, 而这不包括 应用程序的其他部分; 看一看执行类似操作 所需的 纯 CPU 周期, 您会发现,LEA 可以 显著改善执行时间。 使用 LEA 的 平均 [听不清] 要慢于 CPU。 而最终这就表现为采用 LPM0 执行 FFT 的总耗能 约有 27 倍的 耗能改善。 如果看一看 LEA, 其耗能已在右侧列出, 它的耗能改善 约有 20 倍。 这表示正在 由 LEA 执行 特定任务且由 CPU 以并行方式执行 单独任务的 应用程序。 现在, 当然, 了解 LEA 对整个应用程序的 总体影响也非常重要。 这当然会因您的应用程序 不同而存在差异。 在我们的示例中,我们以每秒 从麦克风输出中采集 8kHz 样本的 采样率从 ADC 获得 256 个样本。 我们可以在使用 LEA 和 不使用 LEA 的两种情况下 执行复数 256 点 FFT。 然后,我们 将测量 使用 LEA 加速的 FFT 与未加速 FFT 的 系统耗能。 请注意, 此耗能包括 ADC、麦克风、 模拟前端,并且 显示器处于活跃状态。 看看接下来 两张幻灯片上给出的结果。 您将看到在使用 LEA 的条件下 执行 FFT 相比不使用 LEA 的情况, 能效提升约 20 倍 且速度提升 约 14.5 倍。 您在此可以看到, MSP430 以 8 兆赫运行, 只需约 2,680 微秒 即可执行 256 点 复数 FFT。 如果不使用 LEA,执行此操作 在兆赫频率下约需 9.7 毫秒。 您还将在此 观察到平均电流 包括组合在一起的 信号处理 BoosterPack 以及 Sharp LCD BoosterPack。 不过,再来看看 LEA 如何影响整个 应用程序也许更有用处。 此例情况相同。 我们对 ADC 采样, 执行 FFT, 然后刷新显示屏。 现在,LEA 产生的总体影响 是将能效提高约 1.4 倍。 它还将应用 时间缩短 21%,这意味着主 CPU 现在能够完成更多任务。 让我们来看看 LEA 与 MSP432 仅在执行 FFT 方面的 性能对比情况。 MSP432 基于 Cortex-M4F, 只需 1.5 毫秒即可 执行 256 点复数 FFT。 在耗能比较方面,仅 LEA 的 能效就比 MSP432 大约高 3.3 倍。 在此情况下,LEA 可通过两种方式 帮助您的应用程序。 虽然使用 16 位 MCU 仍能够处理您的 主应用程序,但却在处理、信号 处理以及实时处理方面 面临着计算限制。 而使用 LEA 可以 为您的主应用程序 减轻信号处理负载, 使主 CPU 能够 并行执行任务, 从而提高 应用程序吞吐量。 除并行计算外, 另一方面, LEA 还能够帮助 降低您的 系统耗能, 您可以将信号处理 功能卸载至 加速器。 如先前 幻灯片中所见, 显然,LEA 能够 降低系统耗能, 同时还能够以显著加快的 速度执行信号处理任务
在接下来的 几张幻灯片中,
我将通过考察 LEA 周期 和能效来谈谈 LEA 的性能。
正如前面所述, LEA 是一款用于执行信号处理的
高效加速器。
让我们更仔细地 考察 LEA 的性能,例如,
使用 LEA 而非 CMSIS-DSP 库的 16 位复数 256 点 FFT,
大约比 CM-0+ 快 39 倍,
比 C-M3 快 8 倍, 而且比此处的 C-M4F 快 3 倍。
此外,还注意到 许多执行
512 点 FFT 的 周期都相当线性。
仅就执行 FFT 而言, 这也是显著的性能提升,
尤其是相对于 C-M0+ 内核。
如果您看一看 使用
加速器 LEA 执行 256 点复数 FFT 相对于未加速情况下的耗能影响,
您会发现,在未加速情况下, 只有一个传统 CPU
用于计算 FFT, 而这不包括
应用程序的其他部分; 看一看执行类似操作
所需的 纯 CPU 周期,
您会发现,LEA 可以 显著改善执行时间。
使用 LEA 的 平均 [听不清] 要慢于 CPU。
而最终这就表现为采用 LPM0 执行 FFT 的总耗能
约有 27 倍的 耗能改善。
如果看一看 LEA, 其耗能已在右侧列出,
它的耗能改善 约有 20 倍。
这表示正在 由 LEA 执行
特定任务且由 CPU 以并行方式执行
单独任务的 应用程序。
现在, 当然,
了解 LEA 对整个应用程序的 总体影响也非常重要。
这当然会因您的应用程序 不同而存在差异。
在我们的示例中,我们以每秒 从麦克风输出中采集 8kHz 样本的
采样率从 ADC 获得 256 个样本。
我们可以在使用 LEA 和 不使用 LEA 的两种情况下
执行复数 256 点 FFT。
然后,我们 将测量
使用 LEA 加速的 FFT 与未加速 FFT 的
系统耗能。
请注意, 此耗能包括
ADC、麦克风、 模拟前端,并且
显示器处于活跃状态。
看看接下来 两张幻灯片上给出的结果。
您将看到在使用 LEA 的条件下 执行 FFT 相比不使用 LEA 的情况,
能效提升约 20 倍 且速度提升
约 14.5 倍。
您在此可以看到, MSP430 以 8 兆赫运行,
只需约 2,680 微秒 即可执行 256 点
复数 FFT。
如果不使用 LEA,执行此操作 在兆赫频率下约需 9.7
毫秒。
您还将在此 观察到平均电流
包括组合在一起的 信号处理 BoosterPack
以及 Sharp LCD BoosterPack。
不过,再来看看 LEA 如何影响整个
应用程序也许更有用处。
此例情况相同。
我们对 ADC 采样, 执行 FFT,
然后刷新显示屏。
现在,LEA 产生的总体影响 是将能效提高约 1.4
倍。
它还将应用 时间缩短
21%,这意味着主 CPU 现在能够完成更多任务。
让我们来看看 LEA 与 MSP432 仅在执行 FFT 方面的
性能对比情况。
MSP432 基于 Cortex-M4F,
只需 1.5 毫秒即可 执行 256 点复数 FFT。
在耗能比较方面,仅 LEA 的 能效就比 MSP432
大约高 3.3 倍。
在此情况下,LEA 可通过两种方式 帮助您的应用程序。
虽然使用 16 位 MCU 仍能够处理您的
主应用程序,但却在处理、信号 处理以及实时处理方面
面临着计算限制。
而使用 LEA 可以 为您的主应用程序
减轻信号处理负载, 使主 CPU 能够
并行执行任务,
从而提高 应用程序吞吐量。
除并行计算外,
另一方面, LEA 还能够帮助
降低您的 系统耗能,
您可以将信号处理 功能卸载至
加速器。
如先前 幻灯片中所见,
显然,LEA 能够 降低系统耗能,
同时还能够以显著加快的 速度执行信号处理任务
手机看
扫码用手机观看
 视频简介
视频简介
低能耗加速器(LEA)性能
所属课程:MSP430 16位MCU上的信号处理
发布时间:2019.03.11
视频集数:6
本节视频时长:00:04:38
使用低能加速器(LEA)对16位FRAM MCU进行高级信号处理的介绍和议程
这是具有低能量加速器(LEA)的16位MSP430 FRAM MCU上的高级信号处理培训系列的一部分。






 未学习 MSP430 16位MCU上的信号处理简介
未学习 MSP430 16位MCU上的信号处理简介
 未学习 信号处理概述
未学习 信号处理概述
 未学习 什么是低能耗加速器(LEA)外设?
未学习 什么是低能耗加速器(LEA)外设?
 未学习 低能耗加速器(LEA)性能
未学习 低能耗加速器(LEA)性能
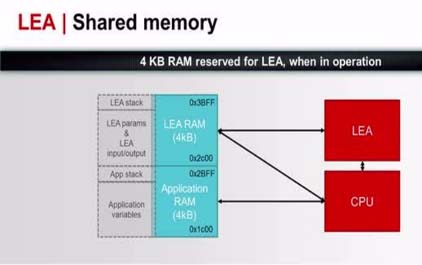 未学习 深入研究低能耗加速器(LEA)外设
未学习 深入研究低能耗加速器(LEA)外设
 未学习 低能耗加速器(LEA)程序员模型
未学习 低能耗加速器(LEA)程序员模型






