
MSP430
最新课程
- 利用EIS技术重新定义BMS的可能性
- IsoShield™技术:隔离电源的未来
- CC35XXE - 基于边缘人工智能的唤醒词检测
- AFE7950EVM入门指南(第1部分)
- ADS9324EVM 开箱及教程
- ADS122S14系列传感器测量精密ADC
- TPS61290 Boost Converter 介绍
- 数字电源控制器简介
- TI 磁感应仿真器 (TIMSS)
- TI 高精度实验室:使用电机驱动器进行设计
热门课程
MSP432产品培训(二)-中断管理



接下来我们看一下Cortex-M
这个内核当中一个独有的可嵌套的一个中断向量管理器NVIC一些具体情况
那所有的以Cortex-M内核2架构 为内核的微控制器
它所有的中断处理都要 通过这个NVIC来进行
那NVIC将整个系统当中的所有的事件分为异常和中断两种
那我们的432产品 它支持 7个异常和71个中断
那所有的中断它分成了 8个可编程的优先级组
它是一个组
然后在组里面还可以区分优先级
那我们在进入中断 和退出中断的时候呢
我们硬件是自动对 环境进行保持和恢复的
我们会保存一些内核寄存器 一些链接寄存器状态 以及PC指针
这些信息都会由硬件 来自动进行出站入站管理
并且产生中断的时候 硬件也是自动 载入一个向量表的中断服务程序地址
那我们这个中断管理也 是支持一个可嵌套可占据的
这样的一个中断性能
另外我们非常有特色的一点呢 我们称之为尾链技术
那尾链技术什么意思呢
就是我们进出中断的时间
它是拥有一个可确定性
就是我们产生了中断
我们需要进行环境的保存
然后是中断服务程序的掉路
那所有这些过程 在我们Cortex-M的架构下
永远是12个周期进入中断
退出中断也是12个周期
这是没有产生尾链的情况
如果产生尾链 所谓的尾链 就是我们在处理一个中断的时候呢
这个中断被打断了 对另外一个中断抢占了
那么我们需要从这个中断来切换 到另外一个中断的服务程序的时候
同样要进行当前的环境的保存和恢复
那这个被抢断的情况下 我们进出 中断的时间是6个周期
这都是一个非常短的时间 并且它是一个可确定性的时间
那它对于一些实时性要求比较高的 应用来说是一个非常有意义的特色
那我们这里具体看一下尾链
假设我们系统当中有两个 中断 一个IRQ1 一个是IRQ2
然后这两个中断它同时发生了
那由于IRQ1的它的优先级 高于IRQ2
那我们系统就将先执行 IRQ1的中断服务程序
接着执行IRQ2的中断服务程序
那我们看到这个列表 第一行 是我们传统的处理器
它将进行的一个出入站管理
首先是push 我们把需要保存的 寄存器信息 PCB信息把它压榨
进行push
然后执行IRQ1的中断程序
等执行完了之后 我们把 入站的东西pop出来
接着我们去执行第二个中断之前 我们同样进行这个push操作
实际上我们等于把刚刚pop出来的 寄存器或输出来数据 我重新把它压榨
然后执行ISR2中断2的服务程序
最后等完毕之后 我们再把 压榨的内容pop出来
这是传统的控制器 它会进行的中断处理
那来看一下我们新的有尾链技术的 Cortex-M4内核它是怎么处理
首先当然要push把要保存的环境变量 来把它入站
这个push 我们刚才说了是一个 固定周期的 它是12个cycles
固定周期的一个入站过程
入站之后我们就执行ISR1 等ISR1执行完毕之后呢
它不会pop 因为我们pop之后 我们要执行ISR2
那我们出站的这些东西 我们又要把它重新入站
这段时间其实是可以节省的
如果不节省就等于又需要 12个cycles 把数据pop出来
再需要12个cycles 把这个数据push进去
那在尾链技术下 我们只需要6个cycles 就可以从ISR1切换到ISR2来进行执行
一直到ISR这些完毕 我们再通过12个cycles把入站信息给pop出来 恢复
所以首先它的入站和 出站的时间是固定的
其次它是非常节省的 它一共节省了18个周期
就是原先需要24个周期来进行push和pop现在只要6个周期来进行尾链处理
我们节省了18个周期
这也是非常可观的一个实时性的性能
好 现在我们来看一下 在用MSP432进行开发的时候
我们怎么样来进行 这个中断向量表的处理
我们这两种方法都是可以的
一种就是我们声明整个中断向量表
这是我们比较通用的原先 430产品通用的这种方法
我们在向量表当中会定义 每个中断服务程序的入口地址
这些代码类似一个标准的函数 它会位于用户应用程序当中
这是我们惯有的一个MSP系列 产品的中断向量表的声明方法
那现在由于我们是用ARM内核
我们也可以用一种新的方法 来进行中断向量表的定义
我们可以使用关键字vector这个 关键字来进行中断向量表的定义
我们可以同时把中断向量 和它的处理函数一起进行定义
就按照这个图上的地址示例就可以了
那可以看到 我们其实减少 很多的代码处理的过程
好 第二部分关于我们Cortex-M内核 这样一个简单的介绍就到此结束
谢谢大家的观看
-
 未学习 MSP432产品培训(一)-MSP432概览(上)
未学习 MSP432产品培训(一)-MSP432概览(上)
-
 未学习 MSP432产品培训(一)-MSP432概览(下)
未学习 MSP432产品培训(一)-MSP432概览(下)
-
 未学习 MSP432产品培训(二)-Cortex-M4F内核
未学习 MSP432产品培训(二)-Cortex-M4F内核
-
 未学习 MSP432产品培训(二)-中断管理
未学习 MSP432产品培训(二)-中断管理
-
 未学习 MSP432产品培训(三)-电源系统
未学习 MSP432产品培训(三)-电源系统
-
 未学习 MSP432产品培训(四)-时钟系统
未学习 MSP432产品培训(四)-时钟系统
-
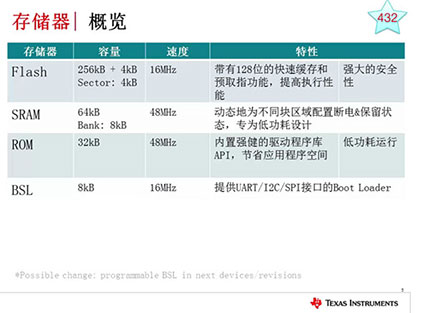 未学习 MSP432产品培训(四)-存储系统
未学习 MSP432产品培训(四)-存储系统
-
 未学习 MSP432产品培训(五)-数字外设
未学习 MSP432产品培训(五)-数字外设
-
 未学习 MSP432产品培训(六)-模拟外设
未学习 MSP432产品培训(六)-模拟外设
-
 未学习 MSP432产品培训(七)-安全与防护
未学习 MSP432产品培训(七)-安全与防护
-
 未学习 MSP432产品培训(八)-软件资源
未学习 MSP432产品培训(八)-软件资源
-
 未学习 MSP432产品培训(九)-MSP430和MSP432平台的代码移植(上)
未学习 MSP432产品培训(九)-MSP430和MSP432平台的代码移植(上)
-
 未学习 MSP432产品培训(九)-MSP430和MSP432平台的代码移植(下)
未学习 MSP432产品培训(九)-MSP430和MSP432平台的代码移植(下)













